
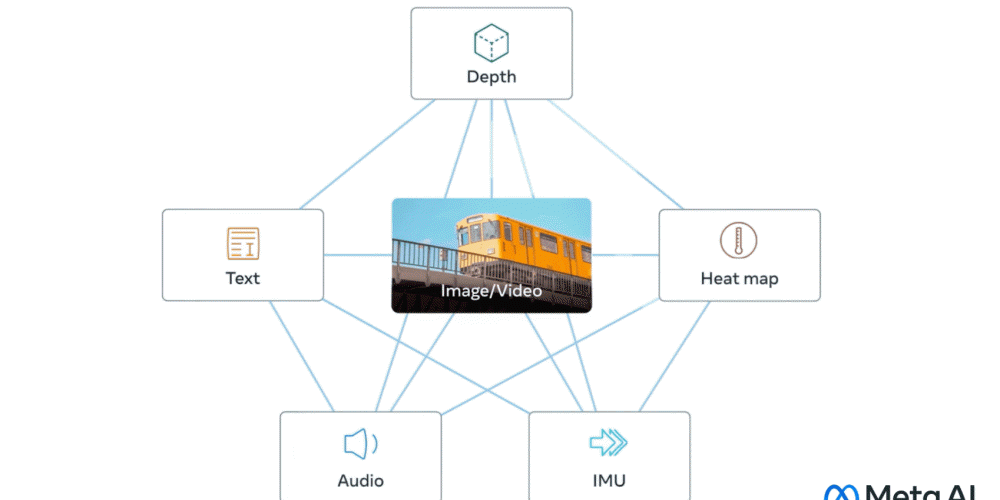
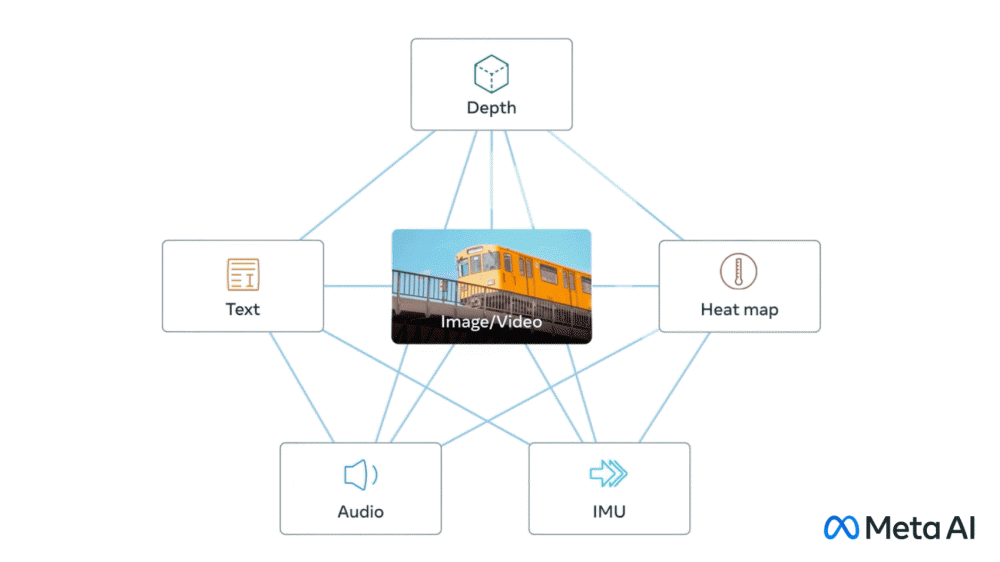
인간은 외부를 인식할 때 많은 거리를 보면서 차 엔진 소리를 듣는 등 시각, 청각, 촉각, 후각, 미각이라는 복수 감각을 동시에 사용한다. 메타 AI 개발 부문인 메타AI가 텍스트, 이미지와 영상, 음성, 움직임을 계산하는 깊이, 적외선에 의한 열, 관성 측정 유닛에 의한 움직임이라는 6가지 데이터를 통합하는 오픈소스 AI 모델인 이미지바인드(ImageBind)를 발표했다.
이미지 인식 AI와 이미지 생성 AI 학습에 이용되는 이미지와 영상, 텍스트를 연결하는 데이터세트는 많다. 이미지바인드는 이미지나 영상, 텍스트 외에 음성과 3D 심도, 열, 움직임이라는 4종류 자가학습용 데이터를 통합한다. 메타에 따르면 열이나 3D 심도는 이미지와 강한 관련성이 있기 때문에 데이터세트 정렬이 용이하다고 한다. 다만 IMU로 측정한 움직임이나 음성에 대해선 상관성이 약하기 때문에 아기 울음소리처럼 시각적 문맥에 따르는 데이터가 된다고 한다.
이미지바인드에서 이미지와 영상을 중심으로 데이터 6개를 통합한 멀티모달 학습을 통해 AI는 리소스를 대량 소비하는 학습 없이 콘텐츠를 더 전체적으로 해석할 수 있다. 기존 이미지 생성 AI는 텍스트로부터 이미지나 영상을 생성할 수 있지만 이미지바인드를 사용하는 것으로 웃음소리나 빗소리로부터 이미지를 생성하는 것도 가능하게 된다고 한다. 예를 들어 작은 생물(Small creature)이라는 텍스트, 숲 이미지, 숲에서 비가 내리는 소리, 새 움직임을 IMU로 측정한 데이터를 프롬프트로 입력한다. 이렇게 하면 비가 내리는 숲속에서 예쁘게 움직이는 작은 생물 애니메이션을 AI로 생성할 수 있다.
메타는 이번 연구에선 6가지 데이터를 통합 검토했지만 촉각과 후각, 뇌 fMRI 신호 등 가능하면 많은 감각을 연결해 더 풍부한 인간 중심 AI 모델이 가능하다고 생각한다고 밝혔다. 다만 멀티모달 학습은 아직 해명되지 않은 게 많아 메타는 이미지바인드가 멀티모달 학습 연구 첫 걸음이 될 것이라고 설명하고 있다. 관련 내용은 이곳에서 확인할 수 있다.






















