


AI 비영리연구기관 오픈API(OpenAI)가 개발한 RND(Random Network Distillation)는 호기심에 따라 환경을 탐색하게 해 강화학습 에이전트를 학습시킨다는 예측 기반 방식이다. 그런데 오픈API가 이런 RND를 이용해 게임 몬테수마의 복수(Montezuma’s Revenge)에서 인간 평균 점수를 상회하는 점수를 내는 등 에이전트 학습에 성공했다고 한다.
RND는 고정되어 있는 임의 신경망이 어떻게 작용할 것인지 예측할 수 없는 익숙하지 않은 상황에서 실행하는 에이전트를 권장한다. 익숙하지 않은 상황에서 어떤 일이 일어날지 예측하는 건 당연히 어렵기 때문에 이에 따른 보상도 커진다.
또 RND는 어떤 강화학습 알고리즘에도 적용하는 게 가능하며 구현이 간단하고 효율적으로 확장할 수 있다는 특징을 지니고 있다.

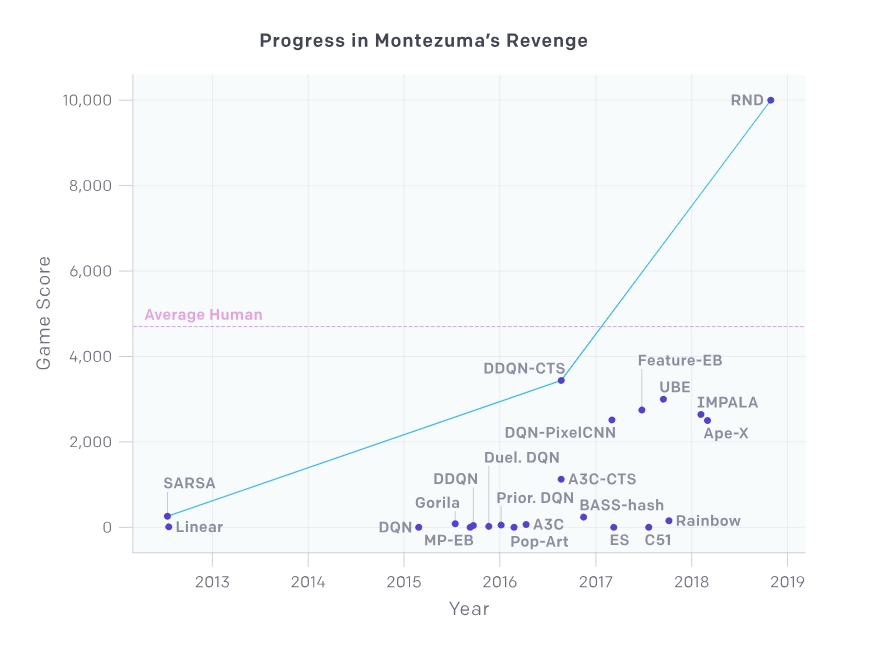
몬테수마의 복수라는 게임을 이용한 건 RND의 정확성을 확인하기 이한 것이다. 이 게임을 선정한 이유는 구글이 개발한 자가 게임 학습 AI인 DQN도 인간 평균 점수인 4,700점을 초과할 수 없었기 때문이다. 몬테수마의 복수 레벨 1에는 객실 24개가 준비되어 있는데 DQN은 15개 밖에 탐색할 수 없었다고 한다.
반면 RND를 이용해 학습한 AI 에이전트는 레벨1 24개 방을 모두 검색할 수 있었다고 한다. 인간 평균 점수를 상회하는 것도 가능하다. 각종 AI 에이전트를 이용해 이 게임을 플레이하도록 하면 인간 평균 점수를 넘어서는 건 RND 밖에 없다고 한다.
몬테수마의 복수는 구글 인공지능인 DQN이 고전한 게임으로 스테이지 높은 곳에서 떨어지거나 해골을 만지거나 주인공이 죽어버리기도 한다.
DQN(Deep Q-Network)은 구글 산하 인공지능 기업인 딥마인드가 개발한 것이다. 기계학습과 신경과학을 응용해 만든 범용 학습 알고리즘. 게임기 화면 출력 신호와 점수를 극대화하라는 간단한 지시만 주어지면 게임에 필요한 규칙은 직접 게임을 여러 번 플레이하면서 학습한다.
DQN은 아타라 2600 게임 49종을 대상으로 한 게임은 몇 시간 만에 모두 마스터했고 49종 가운데 43종은 기존 AI보다 높은 점수를 냈고 29종은 프로게이머보다 높은 점수를 내기도 했다.
하지만 이런 DQN도 앞서 소개한 몬테수마의 복수에는 고전한 바 있다. DQN은 방 1과 2에서 1억 회에 달하는 훈련을 진행하면서 회마다 다른 움직임을 통해 여러 패턴으로 방을 깨는 방법을 찾아갔다. 결과적으론 24개 중 15개를 탐색하는 데 머문 것이다.
이런 이유로 DQN으로 다양한 게임을 테스트한 결과를 보면 인간 이상으로 잘 할 수 있는 게임도 있지만 그렇지 않은 것도 존재하는 것으로 나타나기도 했다. DQN은 앞서 밝혔듯 게임 플레이를 여러 번 반복하면서 시행착오를 통해 배우고 목적을 달성하는 학습 형태, 강화 학습(reinforcement learning)을 이용한다. 이를 통해 자가 학습하고 지식을 축적하는 것이다.
아타리 2600 게임 50종을 대상으로 했을 때 29개에선 인간을 넘어섰지만 몬테수마의 복수에선 0%를 기록했다.
이런 이유로 딥마인드 측은 DQN 알고리즘을 개선하고 학습을 안정화하고 이전 게임 경험을 우선적으로 다루거나 출력 표준화, 수집과 재측정 등을 실시하기도 했다.
지난 7월 오픈AI는 몬테수마의 복수에서 7만 점 이상 높은 점수를 냈다는 발표를 한 바 있다. 오픈AI는 AI 에이전트를 학습하는 과정에는 도타2(Dota2) 같은 5:5 전투에서 인간팀에서 승리한 오픈AI 파이브(OpenAI Five)를 지원하는 강화학습 알고리즘인 PPO(Proximal Policy Optimization)를 이용했다고 한다. 이를 통해 게임 점수 최적화를 도모한 것이다.
당시 오픈AI는 이 게임에서 높은 점수를 내려면 AI 에이전트가 긍정적인 보상으로 이어지는 일련의 행동을 찾아야 하는 탐색, 기억해야 할 일련의 행동과 미묘하게 다른 상황을 일반화해야 하는 2가지 학습 문제를 해결해야 한다고 설명했다.
랜덤으로 작업을 하다가 보상으로 이어지면 AI 에이전트는 이 조치가 보상으로 이어진다는 사실을 기억하고 실제 상황에서 그 행동을 수행할 수 있다. 하지만 더 복잡한 게임이 된다면 보상을 얻을 때까지 일련의 동작이 길어지는 탓에 이런 일련의 작업이 무작위로 발생할 확률도 낮아진다. 다시 말해 강화학습은 일련의 긴 작업이 보상으로 이어질 수 있는 복잡한 게임에서 학습하려면 적합하지 않을 수도 있다는 얘기다. 이에 비해 짧은 액션이 보상을 초래할 간단한 게임에서 잘 동작할 수 있다.

당시 오픈API는 강화학습을 할 때 데모 플레이 데이터 마지막에서 가까운 부분에서 AI 에이전트가 플레이 방법을 학습하도록 방법을 취했다. 이를 반복해 에이전트가 게임을 플레이할 수 있도록 학습을 계속해 인간 플레이어보다 높은 점수를 낸 것이다.
다만 단계별 학습 방법은 처음부터 게임을 배우는 것보다는 훨씬 쉽지만 문제가 많이 있다. 작업의 임의성 탓에 특정 액션 시퀀스가 정확하게 재현되지 않을 수도 있다. 이런 점에선 이런 동일하지 않은 상태를 일반화할 수 있게 될 필요가 있다는 얘기다. 예를 들어 당시 오픈AI의 발표에 따르면 몬테수마의 복수에선 잘 성공해도 다른 게임에선 적용이 잘 안 됐다는 것이다(당시 오픈AI 가 개발한 소스는 깃허브에 공개되어 있다).
또 탐색과 학습 사이의 균형이 필요하다는 문제도 있다. AI 에이전트의 행동이 너무 지나치게 랜덤하면 실수를 연발할 수 있다. 반대로 AI 에이전트의 행동이 너무 정해진 대로 가면 탐험 도중 학습을 그만 두게 된다. 이런 점에서 탐색과 학습 사이의 최적의 균형을 찾아내야 한다는 것이다. 강화학습이 발전되면 랜덤한 노이즈나 매개 변수에 따른 선택에 대해 반응 가능한 알고리즘을 기대할 수 있다.
이런 점에서 RND로 강화한 AI 에이전트는 다양한 가능성을 보여줬다고 할 수 있다. AI 에이전트는 왼쪽이나 오른쪽으로 가면서 열쇠를 획득해 스테이지를 진행한다. 높은 곳에서 떨어지지 않게 발판을 그대로 두고 밧줄이나 단차를 이용해 이동하고 열쇠만 모으는 게 아니라 보석을 모아 점수도 높인다. 또 만지면 사망하는 게이트 틈새도 교묘하게 빠져 나간다. 이렇게 여러 레벨을 깰 수 있는 것.
그냥 게임만 깨는 게 아니라 스테이지에 등장하는 해골과 함께 춤을 추기도 한다. RND를 이용해 학습하면 AI는 생각하지 않던 장난기를 지닌 에이전트를 만들어내는 것도 가능해진다고 할 수 있다.
DQN을 비롯한 인공지능이 이렇게 다양한 작업을 수행할 수 있게 되면 게임 외적인 곳, 건강관리 등 사회에 유익한 활용 방법에도 적용 범위를 넓혀갈 수 있을 것으로 기대할 수 있다.






















