![]()
구글 신경망 기계번역(neural machine translation)에는 번역 이전 문장을 미묘하게 수정하면 번역 후 문장이 크게 바뀌어 버리는 문제가 있다. 이 약점을 극복하기 위해 구글은 새로 인간이 식별할 수 없을 만한 잡신호를 이미지 위에 올려 혼란을 주는 알고리즘(Adversarial Examples. 적대적 사례)을 도입한 번역 모델
구글 트랜스포머(Transformer) 모델을 이용한 신경망 기계번역은 심층신경망을 기반으로 명백한 언어 규칙을 필요로 하면서 종단간 병렬 코퍼스로 번역을 한다. 하지만 앞서 밝혔듯 신경망 기계번역은 입력 정보가 미세하게 바뀌는 것에 민감하다는 약점이 있다. 글 중 한 단어만 동의어로 바꿔도 번역은 전혀 다른 게 되어버릴 가능성이 있다.
신경망 기계번역에 견고성이 부족하기 때문에 시스템에 통합할 수 없다는 기업이나 조직도 있다. 위키피디아도 기계번역에 텍스트 다수를 맡겨 게시한 결과 자체 신뢰도가 손상된다는 지적이 나오기도 했다.

구글은 이 문제를 해결하기 위한 연구를 하고 있다. 지난 6월 발표한 논문도 이 방법 중 하나다. 인간이 식별할 수 없을 만한 잡신호를 이미지 위에 올려놔 번역 모델을 혼란스럽게 하는 적대적 사례(Adversarial Examples)라는 알고리즘을 도입한 것이다. 이 기술은 적대적생성네트워크 GAN에서 영감을 받은 것으로 진위를 판정하는 식별자(Discriminator)에 의존하는 게 아니라 적대적 사례를 학습에 도입하고 훈련 세트를 다양화, 확장한 것이다.
개발팀은 중국어-영어, 영어-독일어 조합에서 번역을 벤치마크한 결과 기존 트랜스포머 모델보다 각각 BLEU 점수가 2.8, 1.6점 향상됐다고 밝혔다.
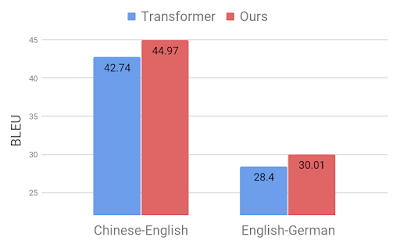
이 같은 연구 결과는 견고성 부족이라는 기존 신경망 기계번역의 약점을 극복할 가능성을 보여줬다는 데에 의미가 있다고 할 수 있다. 새로운 모델은 경쟁 모델과 견줘도 높은 성능을 보여주고 있어 앞으로 다운스트림 작업에 이 번역 모델이 도움이 될 것으로 기대를 모으고 있다. 관련 내용은 이곳에서 확인할 수 있다.