중국 AI 기업 딥시크(DeepSeek)가 2025년 1월 출시한 오픈소스 모델 DeepSeek R1은 AI 업계에 충격을 줬고 그 영향은 주식 시장까지 흔들었다. 그 중에서도 주목받고 있는 건 R1 비용 효율성이다.
R1의 특징은 저렴한 운영 비용. o1 비용이 100만 입력 토큰당 15달러, 100만 출력 토큰당 60달러인 것에 비해 R1 기반 모델인 딥시크 리소너(DeepSeek Reasoner) 비용은 100만 입력 토큰당 0.55달러, 100만 출력 토큰당 2.19달러로 각각 o1 3.6%에 불과하다.
보도에서 R1이 달성한 혁신 중 하나는’순수한 강화학습으로의 전환에 있다고 지적하고 있다. 보통 현행 대규모 언어 모델(LLM) 훈련에는 지도 미세조정(supervised fine-tuning: SFT)이라는 방법이 사용된다. 이는 엄선된 데이터세트로 모델을 훈련시키고 사고의 연쇄(chain-of-thought: CoT)라고 불리는 단계적 추론으로 학습시키는 것으로 모델의 추론 능력 향상에 필수적이라고 여겨져 왔다.
하지만 R1은 SFT를 거의 사용하지 않고 대부분 강화학습만으로 훈련했다. 이 접근법으로 모델은 복잡한 문제에 추가 처리 시간을 할당하고 난이도에 기반해 작업 우선 순위를 정하는 예상치 못한 능력을 발전시켰다. 딥시크 연구진은 기술 보고서에서 이 현상을 아하 체험(Aha moment)이라고 부른다. 개발 최종 단계에서 제한적으로 SFT가 사용됐지만 딥시크가 대부분 강화학습만으로 성능을 크게 향상시킨 점을 높이 평가하고 있다.
또 다른 주목점은 적은 기계 자원으로 개발된 점이다. 딥시크는 중국 헤지펀드(High-Flyer Quant)를 전신으로 2023년 설립된 기업으로 이 헤지펀드는 미국 수출 규제가 발동되기 전 엔비디아 GPU 1만 개를 확보하고 규제 강화 후에는 대체 경로를 통해 GPU를 5만 개까지 확대했다.
이렇게 조달된 GPU는 규제 준수를 위해 칩 간 전송 속도를 낮춘 엔비디아 H800이라고 알려진 한편 일부 보도에서는 중국이 규제를 피해 고급 칩을 국내로 반입하고 있다고도 전해지고 있다.
그렇더라도 5만 개라는 수는 오픈AI, 구글, 앤트로픽 등 대형 AI 연구소가 50만 개를 넘는 GPU로 AI를 운용하는 것에 비하면 적다고 할 수 있다. 보도에선 한정된 자원으로 경쟁력 있는 결과를 낸 딥시크 능력은 최첨단 LLM을 훈련시키는 고비용 패러다임에 창의력과 기지가 어디까지 도전할 수 있는지를 부각시켰다고 말했다.
또 가중치가 공개된 오픈웨이트 모델이라는 점도 R1이 주목받는 이유 중 하나다. 주요 오픈소스 모델로 선행하고 있는 메타 Llama조차 프롬프트로 적극적으로 지시하지 않으면 CoT 과정을 표시하지 않지만 R1은 기본적으로 답변의 CoT를 투명하게 표시한다고 한다.
하지만 기술 보고서로 연구 결과가 공개됐다는 건 경쟁 모델이 곧바로 이를 적용해 따라잡을 수 있다는 의미이기도 해 R1 혁신은 압도적인 선두를 확립하는 무기가 되지는 않는다. 메타나 미스트랄AI 같은 오픈소스 모델 기업이라면 몇 달 안에 따라잡을 수 있을 것으로 보인다고 한다.
또 R1에는 천안문 사건에서 중국 정부가 자행한 잔혹한 탄압에 관한 질문에 답하지 않는 등 윤리적 문제도 지적되고 있다.
많은 개발자는 이런 편향이 에지케이스 그러니까 극단적인 예이며 미세조정으로 완화할 수 있다고 보고 있다. 예를 들어 메타 Llama는 데이터세트가 공개되지 않아 숨겨진 편견이 있다는 비난과 저작권 침해 소송 등에 직면했지만 여전히 인기 있는 오픈 모델로 남아있다.
오픈AI와 오라클, 소프트뱅크 등이 주도하는 거대 AI 투자 계획 스타게이트 프로젝트(Stargate Project)와 저비용 AI를 실현한 딥시크를 대비시키 스타게이트 프로젝트는 범용 인공지능(AGI) 실현에는 전례 없는 계산 자원이 필요하다는 신념에 기반하고 있지만 딥시크가 적은 비용으로 고성능 모델을 입증한 건 이 접근법 지속가능성에 대한 시험이며 막대한 투자에 걸맞은 성과를 낼 오픈AI 능력에 의문을 제기하는 것이라고 말했다. 관련 내용은 이곳에서 확인할 수 있다.
한편 이렇듯 딥시크가 대기업이 막대한 비용과 시간을 들여 완성한 AI 모델보다 뛰어나다고 평가받는 R1을 발표하고 기존 모델보다 훨씬 적은 비용으로 트레이닝했다는 사실이 밝혀지면서 투자자 사이에서 트레이닝에 사용되는 엔비디아 칩 가치에 의문이 제기되어 엔비디아 주가가 하루 만에 17%나 하락했다. 이에 엔비디아는 딥시크 추론 실행에는 상당한 엔비디아 칩이 필요하다고 긴급 발표하며 신뢰 회복을 도모했다.
딥시크 모델이 낮은 비용으로 개발됐다는 사실은 엔비디아 기업 가치에 어두운 그림자를 드리웠다. 딥시크는 중국 기업이지만, 중국은 미국으로부터 엄격한 칩 수출 제한을 받고 있는 것으로 알려진 국가 중 하나다. AI 모델 트레이닝이나 추론에 사용되는 고성능 칩은 완전히 차단되어 있어 엔비디아 등은 중국향으로 성능을 억제한 칩을 개발해 수출하고 있지만 오픈AI가 사용하는 칩과는 성능에 상당한 차이가 있다고 한다.
하지만 성능이 억제된 칩으로 오픈AI 모델을 능가하는 게 개발되면서 지금까지 많은 기업이 막대한 투자를 해온 칩 유용성에 의문이 제기되어 엔비디아 주가가 하락한 것. 보도에 따르면 1월 27일 미국 기술주 전반이 하락했고 그 중에서도 엔비디아는 2020년 이래 최악의 하락폭인 17% 감소를 기록했다. 엔비디아 시가총액은 5,888억 달러 정도 하락했다고 한다.
또 반도체 기업 마이크론(Micron)은 11% 이상, Arm은 10% 이상, 브로드컴은 17% 이상, AMD는 6% 이상 하락했으며 에너지 관련에서도 비스트라(Vistra)가 28%, 콘스텔레이션에너지(Constellation Energy)가 21% 하락하는 등 딥시크 등장은 AI 업계를 크게 흔들어 놓았다.
이런 상황에 엔비디아는 성명을 발표하고 딥시크 추론에는 대량 엔비디아 칩과 고성능 네트워킹이 필요하다고 주장했다. 더불어 딥시크가 중국향 엔비디아 칩 H800을 2,000개 사용해 트레이닝했다는 사실이 밝혀진 것과 관련해 엔비디아는 이는 중국 시장에서 자사 칩의 유용성을 보여주는 것이며 딥시크 서비스 수요를 충족하려면 앞으로도 많은 칩이 필요할 것이라고 덧붙였다.
한편 H800은 엔비디아가 미국 수출 규제에 준수해 특별히 설계한 칩이지만 2023년 10월 지목되어 규제를 받았다. 이에 따라 지금은 중국이 H800을 구입하는 건 불가능하다.
엔비디아는 딥시크 활약을 환영하며 딥시크는 널리 구입 가능한 모델과 수출 규제에 완전히 준수한 장비를 활용해 새로운 모델을 만드는 사례를 보여줬다고 밝혔다. 관련 내용은 이곳에서 확인할 수 있다.
다시 정리하면 AI 전문가가 R1에 놀란 이유는 3가지다. 첫째는 미국 수출 규제로 최첨단 GPU에 접근할 수 없는 딥시크가 성능이 높지 않은 중국향 칩인 엔비디아 H800을 사용해 단지 600만 달러로 R1을 훈련시켰다는 점이다. 이 비용은 일부 보도를 통해 밝혀진 o1의 훈련 비용 3%에 불과하다.
둘째는 오픈AI가 2024년 9월에 o1을 발표한 지 불과 4개월 만에 R1이 등장했다는 점. 그리고 가장 중요하다고 여겨지는 셋째는 딥시크가 R1 모델 가중치를 오픈한 MIT 라이선스로 무료 배포했다는 점이다. 이는 챗GPT와 같은 폐쇄형 모델과는 달리 누구나 다운로드해서 실행하거나 조정할 수 있다는 걸 의미한다.
이런 점으로 인해 R1은 AI 커뮤니티에서 갑자기 화제가 되어 아이폰 앱스토어 무료 앱 카테고리에서 챗GPT를 제치고 1위로 올라섰다.
미국 과학계에 충격을 준 소련의 세계 최초 인공위성에 빗대어 AI판 스푸트니크 쇼크라고도 불리는 R1 등장이 준 임팩트로 인해 미국 주식 시장은 패닉에 빠졌고 R1이 엔비디아 GPU로 만들어졌음에도 불구하고 엔비디아 주가는 앞서 밝혔듯 1월 27일 16.9% 하락했으며 시가총액 세계 1위 기업이었던 엔비디아는 단 하루 만에 3위로 추락했다.
이 주가 하락으로 엔비디아 시가총액 5,888억 달러가 사라졌고 메타가 2022년 기록한 2,400억 달러보다 2배 이상 차이를 두며 역대 최악의 손실을 기록했다.
AI 가속기 시장에서 거의 독점적 지위를 차지하고 있던 칩메이커로서 군림하던 엔비디아의 추락으로 광범위한 종목이 매도됐고 하이테크 주식을 중심으로 한 나스닥은 3.1%, S&P500 지수도 1.5% 하락했다.
충격은 비기술 기업에도 파급되어 AI 데이터센터에 전력을 공급하며 주가가 급등했던 에너지 관련 주식도 일제히 하락했다. 또 발전기 동력원인 천연가스 선물 가격은 5.9% 하락했고 석유도 2% 이상 하락했다.
주식 시장 동요에 대해 투자회사 서드세븐캐피털(Third Seven Capital) 시장 전략가인 마이클 블록은 딥시크 위협이 실제인지 여부는 시간이 지나면 알 수 있을 것이라며 어떤 기술이 작동할지 그리고 서구 대기업이 어떻게 대응하고 진화할지를 둘러싼 경쟁이 시작됐다고 지적한 뒤 시장은 트럼프 정권 2.0 시작에 방심하고 있었고 하락할 구실을 찾고 있었을지도 모른다면서 그런 시점에 더할 나위 없는 구실이 발견됐다고 분석했다.
한편 딥시크가 실제로 AI 분야에서 서구의 우위를 흔들 만한 것인지에 대해서는 냉정한 목소리도 있다. 투자회사 얼라이언스번스타인(AllianceBernstein) 애널리스트는 딥시크 모델은 훌륭하지만 기적이라고 할 정도는 아니라며 우리가 아는 AI 인프라 복합체의 종말을 알리는 종에 대한 패닉은 과장됐다고 논평했다.
또 미국 최고 상용 모델에 필적하는 저가 오픈웨이트 AI 모델 등장은 폐쇄형 소스 AI 기업에게는 순수한 위협이지만 급속한 AI 진보를 지켜봐 온 이들에게는 그다지 놀랄 만한 것이 아니라며 컴퓨팅 역사에는 정보기술이 더 저렴하고 콤팩트해지며 상품화된 뒤 더 큰 제품 일부로 흡수되어 온 사례가 수없이 많다고 말했다. 관련 내용은 이곳에서 확인할 수 있다.
한편 AI 개발팀 언슬로스(unsloth)가 DeepSeek-R1 모델을 일반 사용자도 더 쉽게 사용할 수 있도록 동적 양자화라는 방법으로 규모를 크게 압축하는 데 성공했다고 보고했다.
양자화는 데이터 정밀도를 낮춰 크기를 줄이는 기술. 예를 들어 32비트 부동소수점(FP32)에서는 0.123456과 같은 세밀한 수치를 표현할 수 있지만 이를 8비트 정수(INT8)로 변환하면 0부터 255까지의 정수로 변환된다. 물론 정밀도는 떨어지지만 대신 데이터 크기는 4분의 1로 줄어든다.
양자화를 통해 메모리 사용량이 줄어들거나 계산 속도가 향상되거나 전력 소비를 줄여 더 효율적인 계산이 가능해진다. 다만 과도한 양자화는 정밀도 저하를 초래할 수 있어 적절한 균형이 필요하다.
언슬로스는 DeepSeek-R1의 아키텍처를 분석한 뒤 모델 각 부분에 대해 서로 다른 압축률로 양자화하는 동적 양자화를 진행했다. 이를 통해 원래 모델 크기가 720GB였던 것을 131GB까지 80% 축소를 실현했다고 보고했다.
예를 들어 전체 가중치 0.5%를 차지하는 모델 첫 3개 층은 중요한 역할을 하기 때문에 4비트 또는 6비트로 양자화됐다. 또 MoE(Mixture of Experts) 층에서 사용되는 복수 전문가(Experts) 모델은 전체 가중치 1.5%를 차지하며 6비트로 양자화됐다. 더불어 어텐션(Attention) 기구 모듈은 모의 성능에 중요한 영향을 미치기 때문에 4비트 또는 6비트로 양자화됐다.
그 중에서도 연산에서 중요한 처리를 담당하는 ‘down_proj’라는 레이어는 비교적 높은 정밀도로 양자화됐다. 언슬로스가 동적 양자화한 DeepSeek-R1에는 1.58비트 버전(모델 크기 131GB), 1.73비트 버전(모델 크기 158GB), 2.22비트 버전(모델 크기 183GB), 2.51비트 버전(모델 크기 212GB) 4가지가 있으며 down_proj 레이어는 각각에서 다른 설정으로 양자화됐다.
전체 가중치 88%를 차지하는 레이어는 1.58비트라는 낮은 정밀도로 양자화해 크게 크기를 줄이는 데 성공했다. 모든 레이어를 같은 방식으로 양자화하면 무한 루프나 의미 불명 출력 같은 문제가 발생하지만 동적 양자화로 이런 문제를 피할 수 있었다는 설명이다.
동적 양자화된 DeepSeek-R1은 VRAM과 RAM을 합해 80GB 이상인 환경에서 최적으로 작동했다. 구체적인 성능으로는 처리량에서 초당 140토큰, 단일 사용자 추론에서 초당 14토큰을 달성했다. GPU가 없어도 20GB RAM이 있으면 작동 가능하지만 그 경우 처리 속도가 느려진다.
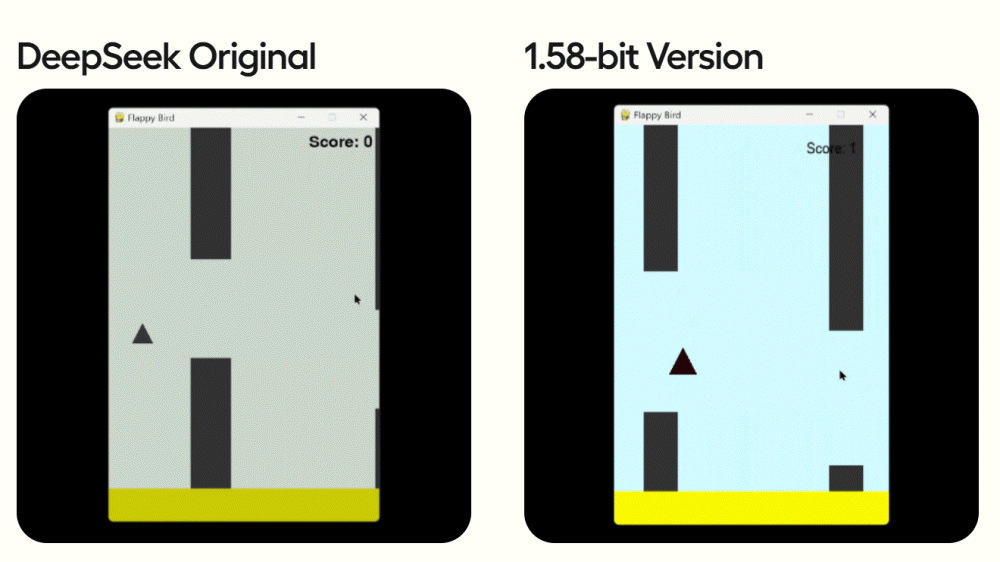
검증을 위해 언슬로스는 플래피버드(Flappy Bird) 스타일 게임 코드 작성을 시켜 각 모델 성능을 평가했다. 그 결과 1.58비트 버전에서도 충분히 실용적인 성능을 유지하고 있다는 게 확인됐다고 보고했다.
언슬로스가 동적 양자화한 4개 모델은 허깅페이스에 공개됐으며 llama.cpp나 Ollama, vLLM 등 다양한 프레임워크에서 사용할 수 있다. 관련 내용은 이곳에서 확인할 수 있다.
이렇듯 딥시크 추론 모델 등장이 화제가 되고 있는 가운데 미 해군이 업무용과 개인용 모두 딥시크 AI를 사용하지 말라고 지시한 것으로 밝혀졌다.
미 해군은 딥시크 AI가 편리하더라도 보안상 우려 및 윤리상 우려가 있다며 어떤 형태로도 사용해서는 안 된다고 이메일로 통달했다는 것. 이메일은 새로운 AI 딥시크에 관한 중요한 최신 정보 안내로 배포됐으며 딥시크 AI에 대해 업무 관련 태스크와 개인적 용도 모두에 사용하지 않는 게 필수라며 사용을 금지하는 내용을 담고 있다.
미 해군 측은 보도에서 언급한 이메일이 해군 최고정보책임자가 생성 AI 정책에 근거해 발신한 게 맞다고 인정했다. 미국에는 적대적 외국 그러니까 중국 등에서 개발·운영되는 플랫폼이나 애플리케이션을 경계하는 움직임이 있으며 바이든 정권 하에서 제정된 미국인을 해외 적대자가 관리하는 애플리케이션으로부터 보호하는 법률, 일명 틱톡 금지법으로 인해 인기 앱 틱톡이 일시적으로나마 서비스를 중단하는 사태도 발생했다. 그 이후로도 앱스토어에서의 배포는 재개되지 않고 있다.
백악관은 국가안전보장회의가 딥시크의 국가 안보에 대한 영향을 검토할 예정이라고 밝혔다. 관련 내용은 이곳에서 확인할 수 있다.

그 뿐 아니라 데이터 유출 위험으로 인해 수백 개 기업이 딥시크를 차단한 것으로 밝혀졌다. 보도에 따르면 수백 개에 이르는 기업 그 중에서도 미국 정부와 관련된 기업이 딥시크 관련 서비스를 차단했다고 한다. 사이버보안 기업 아르미스(Armis)와 넷스코프(Netskope) 임원 인터뷰를 바탕으로 수백 개 기업이 딥시크를 차단했다고 보도한 것. 아르미스 나디르 이스라엘 CTO는 가장 큰 우려는 AI 모델 데이터가 중국 정부에 유출될 가능성이라고 말했다.
블룸버그가 제공하는 온라인 법률 조사에 데이터 분석과 AI를 사용하는 구독 서비스인 블룸버그로(Bloomberg Law)와 샌프란시스코 법률사무소인 폭스포스차일드(Fox Rothschild)도 딥시크를 차단했다고 보도했다.
딥시크 개인정보 보호정책에 따르면 딥시크는 모든 사용자 데이터를 중국 서버에 저장한다. 중국 법률상 기업은 요청 시 정보기관과 데이터를 공유하는 게 의무화되어 있어 많은 기업이 데이터 유출을 우려해 딥시크 사용을 금지하는 것으로 보인다.
한편 이탈리아 데이터보호당국이 딥시크 앱 사용자 데이터 취급에 대해 정보 제공을 요구한 뒤 이탈리아 앱스토어에서 딥시크 앱이 사라졌다.
미국에서는 미 해군이 가장 먼저 딥시크 제품 사용을 전면 금지했으며 국방부에서도 딥시크 사용이 금지된 상태다. 또 딥시크 데이터베이스에서 채팅 이력 등 데이터 수백만 건이 유출될 수 있는 상태였다는 지적도 제기됐다. 관련 내용은 이곳에서 확인할 수 있다.
그런가 하면 AI 업계에서 리더 격인 오픈AI 샘 알트만 CEO가 저비용 고성능 AI 모델을 개발했다고 업계에서 화제가 된 중국발 AI 기업 딥시크에 대해 DeepSeek-R1은 인상적인 모델이지만 더 뛰어난 AI를 발표할 예정이라고 엑스에서 발언했다.
deepseek's r1 is an impressive model, particularly around what they're able to deliver for the price.
— Sam Altman (@sama) January 28, 2025
we will obviously deliver much better models and also it's legit invigorating to have a new competitor! we will pull up some releases.
알트만 CEO는 1월 28일 자신의 엑스 계정을 업데이트하며 딥시크 R1은 가격 대비 기능을 제공하는 점에서 인상적인 모델이지만 분명히 자사는 R1보다 우수한 모델을 제공할 수 있고 새로운 경쟁자가 있다는 건 정말 자극적인 일로 앞으로 몇 가지 릴리스를 발표할 예정이라고 말했다.
그는 또 하지만 자사는 주로 연구 로드맵을 지속적으로 실행하는 것에 흥분하고 있으며 자사 사명을 성공시키려면 이전보다 컴퓨팅이 더 중요하다고 생각한다면ㄴ서 세계는 AI를 대량으로 사용하길 원하고 있으며 차세대 모델이 등장하면 정말 놀라운 일이 될 것이라고 게시했다. 마지막으로 범용 인공지능(AGI)과 그 이상을 제공할 수 있기를 기대한다고 밝혔다.
한편 알트만 CEO는 지난 2023년 6월 열린 인도 벤처캐피털 대상 회의에서 진행된 질의응답 중 인도 엔지니어로부터 1억 달러가 아닌 1,000만 달러로 정말 큰 걸 만들 수 있냐는 질문을 받았을 때 상당히 경멸적인 태도로 잘 들으라며 이런 방식은 기초 모델 트레이닝에서 자사와 경쟁하는 건 전혀 가망이 없다는 걸 전하는 것과 같다면서 그건 상당히 가망이 없다고 생각한다면서 1,000만 달러 스타트업으로는 오픈AI와 맞설 수 없다고 했다.
이 발언을 발견한 기업가 아르노 베르트랑 등은 지금 돌이켜보면 상당히 우스꽝스러운 발언이라며 알트만 CEO 발언을 조롱했다. 한편 딥시크는 AI 모델 R1 트레이닝에 드는 비용이 겨우 560만 달러라고 주장했다. 관련 내용은 이곳에서 확인할 수 있다.
한편 오픈AI는 딥시크가 자사 이용약관을 위반하는 데이터 증류를 통해 자체 AI 모델을 훈련했다고 발표하고 이에 대한 증거도 확보했다고 밝혔다.
오픈AI는 딥시크 데이터 증류 증거를 여러 건 발견했다고 밝혔다. 증류는 개발자가 더 크고 성능이 뛰어난 AI 모델 출력을 사용해 더 작은 AI 모델을 우수한 성능으로 훈련하는 기법. 이 기법을 통해 AI 모델로 특정 작업을 훨씬 낮은 비용으로 구현할 수 있다.
증류는 업계에서 일반적인 기법이지만 오픈AI는 이용약관에 사용자가 오픈AI 서비스를 복사하거나 오픈AI와 경쟁하는 모델을 개발하기 위해 출력을 사용할 수 없다고 명시하고 있어 딥시크가 자체 AI 모델 구축을 위해 오픈AI 데이터를 증류했다면 이용약관 위반에 해당한다.
오픈AI 관계자는 문제가 되는 건 자신의 목적을 위해 자신의 모델을 만들기 위해 플랫폼에서 데이터를 가져가는 경우라고 말했다. 다만 오픈AI는 딥시크 측 증류에 대해 추가 설명이나 자세한 내용 제공을 거부했다.
오픈AI와 파트너사인 마이크로소프트는 2024년 오픈AI API를 사용한 것으로 추정되는 딥시크 계정을 조사했고 이용약관을 위반하는 증류 행위를 차단했다. 이에 대해 마이크로소프트는 논평을 거부했으며 오픈AI도 세부사항에 대한 언급을 하지 않았다.
딥시크의 오픈AI 데이터 증류 의혹에 대해 트럼프 정부 AI 및 암호화폐 책임자였던 데이비드 삭스는 지적재산권 도용이 발생했을 가능성이 있을 수 있다고 언급했다. AI에는 증류라는 기술이 있어 한 모델이 다른 모델로부터 학습해 부모 모델 지식을 흡수할 수 있다고 밝혔다.
일부 전문가에 따르면 V3는 오픈AI GPT-4 출력으로 훈련됐음을 보여주는 응답을 생성한다고 한다.
업계 관계자에 따르면 중국과 미국 AI 연구소에서는 오픈AI 같은 기업 출력을 사용하는 게 일반적이라고 한다. AI 모델이 더 인간다운 응답을 생성할 수 있도록 인력 채용에 투자하고 있으며 중소기업은 종종 이 작업에 전적으로 의존하고 있다고 내부 관계자는 전했다.
캘리포니아 대학 버클리캠퍼스의 AI 박사과정생인 리트윅 굽타는 스타트업이나 학자가 챗GPT 같은 인간과 연계된 상용 대규모 언어 모델(LLM) 출력을 사용해 다른 모델을 훈련하는 건 매우 일반적이라며 딥시크가 같은 일을 하고 있다고 해도 놀랍지 않다면서 만일 사실이라면 이런 행위를 정확히 막기는 어려울 수 있다고 말했다.
한편 오픈AI는 중국 기반 기업이나 다른 기업이 미국 대형 AI 기업의 모델을 항상 추출하려 한다는 걸 알고 있다는 성명을 발표했다. 또 미국 기술을 빼앗으려는 적대자나 경쟁자 시도로부터 가장 성능이 뛰어난 AI 모델을 보호하기 위해 미국 정부와 긴밀히 협력하는 것이 중요하다고 말했다. 관련 내용은 이곳에서 확인할 수 있다.
어쨌든 R1 트레이닝 비용은 오픈AI 추론 모델인 o1 3% 수준으로 전해지며 AI 개발 업계 시각을 딥시크가 크게 바꾸고 있는 건 분명하다. 이런 딥시크에 대해 레딧(Reddit) 전 CEO이자 환경보전단체 테라포메이션(Terraformation)을 운영하는 이샨 웡이 설명했다.
DeepSeek-R1-Zero와 DeepSeek-R1 출시는 미국 과학계에 충격을 준 소련이 선보인 세계 최초 인공위성에 빗대어 AI판 스푸트니크 쇼크로 표현되고 있다. 하지만 웡은 DeepSeek-R1 등장은 스푸트니크 등장 순간보다는 오히려 구글이 등장한 순간에 가깝다고 말한다.
그에 따르면 소련은 스푸트니크로 당시 미국이 할 수 없었던 인공위성 발사가 가능함을 보여줬지만 스푸트니크의 기술적 세부 사항이나 설계도를 공개하지는 않았다. 하지만 DeepSeek-R1은 오픈소스화되어 있어 캘리포니아 대학 버클리 캠퍼스 연구실이 출시 후 단 하루 만에 DeepSeek-R1 성능 재현성을 확인했다.
마찬가지로 구글은 2004년에 분산형 알고리즘을 사용해 일반 컴퓨터를 네트워크로 연결하고 비용 대비 성능이 뛰어난 슈퍼컴퓨터 클러스터를 구축한다는 목론서 S-1을 제출하고 상장했다. 당시 하이테크 기업은 대형 메인프레임을 구매해 슈퍼컴퓨터를 구축하는 게 보통이었으며 구글의 비용 대비 성능이 뛰어난 구축 방식은 혁신적이었다.
I think the Deepseek moment is not really the Sputnik moment, but more like the Google moment.
— Yishan (@yishan) January 28, 2025
If anyone was around in ~2004, you'll know what I mean, but more on that later.
I think everyone is over-rotated on this because Deepseek came out of China. Let me try to un-rotate…
이후 구글은 대규모이면서 비용 효율이 높은 강력한 슈퍼컴퓨터를 관리·제어하기 위해 사용하는 알고리즘에 관한 논문(MapReduce, Bigtable)을 공개했다. 이 논문을 기반으로 현대에는 거대한 데이터세트에 대한 분산형 컴퓨팅에 맵리듀스가 사용되고 있으며 빅테이블은 데이터 저장 시스템으로서 구글 맵, 구글 어스, 유튜브 등 다양한 애플리케이션을 지원하고 있다.
이를 바탕으로 웡은 딥시크는 구글 등장 순간과 매우 비슷하다며 구글은 본질적으로 자신이 뭘 했는지 설명하고 다른 이들에게도 어떻게 하면 그게 가능한지 가르쳐줬다고 말했다. 한편 구글의 경우 자신들이 하고 있는 일을 세상에 공표하고 나서 그 방법을 보여주는 논문을 발표하기까지 상당한 시간이 걸렸다며 이와 대조적으로 딥시크는 모델 발표와 동시에 논문을 발표했다고 말했다.
또 이번 딥시크 발표로 엔비디아나 오픈AI, 메타, 마이크로소프트, 구글 등이 죽었다고는 생각할 수 없다며 확실히 딥시크는 강력한 신흥기업이지만 AI 세계에서는 종종 일어나는 일이라면서 몇 달 뒤에는 모두가 딥시크 수법을 모방할 것이고 추론에 필요한 비용도 싸질 것이라고 웡은 예측했다.