메타가 1,100개 이상 언어로 음성으로부터의 문자 발생이나 문장을 읽을 수 있는 음성 인식 모델인 MMS(Masively Multilingual Speech)를 발표했다. MMS는 기존 대규모 다언어 음성 인식 모델을 크게 상회하는 언어에 대응하고 있어 화자가 적은 언어에서도 다양한 정보에 접근하기 쉬워질 것으로 기대되고 있다.
메타는 이전부터 전 세계 언어를 실시간으로 번역하는 AI인 바벨피쉬(Babelfish) 개발을 발표하는 등 음성 인식과 번역 AI 개발에 주력해왔다. MMS에 대해 발표한 글에서 메타는 음성을 인식, 생성하는 능력을 기계에 갖게 해 음성만으로 정보에 액세스하고 있는 사람을 포함해 더 많은 사람이 정보에 액세스할 수 있게 된다고 밝히고 있다.
Today we're sharing new progress on our AI speech work. Our Massively Multilingual Speech (MMS) project has now scaled speech-to-text & text-to-speech to support over 1,100 languages — a 10x increase from previous work.
— Meta AI (@MetaAI) May 22, 2023
Details + access to new pretrained models

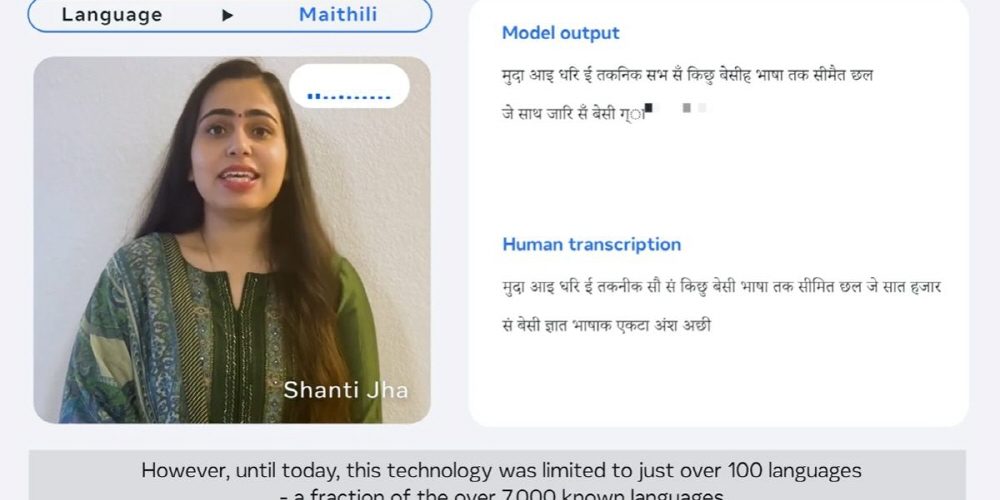
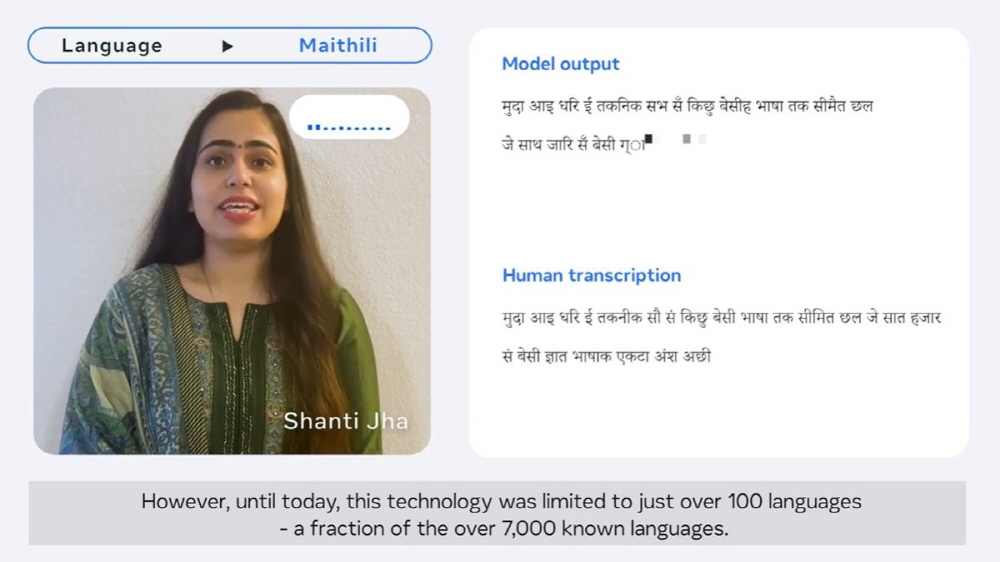
고품질 기계학습 모델을 생성하려면 많은 라벨링 데이터가 필요하며 음성 인식 모델의 경우 수천 시간 음성과 문자 발생 데이터가 필요하다. 하지만 지구상에서 말하고 있는 7,000개 이상 언어 중 대부분은 이런 질 높은 데이터가 존재하지 않고 기존 음성 인식 모델은 100여 개 언어를 커버하고 있는 것에 그치고 있다고 한다.
따라서 메타는 라벨이 없는 데이터에서 학습할 수 있는 자가 교사가 있어 학습을 채용한 음성 인식 프레임워크 Wav2vec 2.0을 이용해 MMS 프로젝트에 있어 화자가 적은 언어에 있어 라벨 첨부 데이터 부족을 극복했다고 밝히고 있다. 또 메타는 프로젝트 일환으로 1,100개 이상 언어에 걸친 성경 읽기 데이터세트를 만들고 MMS를 학습하고 있다. 성경을 비롯한 종교 문헌은 다양한 언어로 번역되고 있으며 텍스트 기반 언어 번역 연구를 위해 널리 연구되고 있기 때문에 음성 인식 모델 개발에도 유용하다고 한다.
MMS는 1,107개 언어로 텍스트 생성이나 문장 읽기에 대응하고 있으며 4,000개 이상 언어를 식별할 수 있다고 한다. 학습에 사용한 음성 데이터는 남성 화자에 의해 읽혀지는 게 많았지만 메타 분석에 따르면 MMS는 남성 음성과 여성 음성에 대해 거의 동등하게 기능하는 걸 나타내고 있다. 음성 인식 에러율을 조사한 결과를 보면 남성 에러율은 12.3이고 여성 에러율은 12.4다. 또 자가 교사 학습을 채택한 Wav2vec 2.0을 이용해 학습된 MMS는 언어 수가 61에서 1,107로 증가해도 오류율이 0.4% 밖에 증가하지 않았다고 한다.
메타는 전 세계에서 수많은 언어가 사라지는 위기에 직면하고 있으며 음성 인식과 음성 생성 기술 한계가 이런 추게를 더 가속화할 것이라며 자신이 좋아하는 언어로 정보에 접근하고 기술을 활용하고 있어 언어가 유지되는 세계를 구상하고 있다고 밝혔다. 메타는 연구 커뮤니티가 MMS를 기반으로 추가 연구를 진행할 수 있도록 모델과 코드를 깃허브에 올리고 있다. 관련 내용은 이곳에서 확인할 수 있다.