구글 산하 인공지능 기업인 딥마인드(DeepMind)가 인공지능을 통해 멀티태스킹 학습을 진행할 때 발생하는 보상 차이를 메우기 위한 기술인 팝아트(PopArt)를 개발했다.
딥마인드는 국내에서도 이세돌 9단을 꺾어 인공지능 열풍을 불러온 인공지능 알파고(AlphaGo)를 개발하는 한편 강화학습을 통해 게임을 스스로 배워 인간보다 더 잘 해내는 인공지능인 DQN 등을 개발하기도 했다.
이런 딥마인드가 이번에 팝아트를 개발한 이유는 이렇다. 에이전트 하나가 여러 작업을 해결할 수 있는 방법을 배울 수 있게 해주려는 멀티태스킹 학습이 필요하다. 멀티태스킹 학습은 인공지능 연구에선 오랜 목표 중 하나다. 앞서 밝힌 DQN 같은 에이전트도 여러 게임을 하면서 스스로 배우고 멀티태스킹 학습을 할 수 있는 알고리즘을 이용한다. 이렇게 인공지능 연구가 더 복잡해지면서 관련 연구에선 여러 전문 에이전트를 설치하는 게 현재 주류를 이루고 있다.
이런 상황이다 보니 여러 에이전트를 학습시키는 알고리즘은 여러 작업을 단일 에이전트를 통해 구축할 수 있어야 한다. 멀티태스킹 학습 알고리즘이 중요해지는 것. 하지만 이런 멀티태스킹 학습 알고리즘에는 문제가 하나 있다. 강화학습 에이전트가 성공을 결정하는 이용하는 보상 배율이 각각 다르다는 것이다.
예를 들어보자. DQN에 게임 퐁을 학습시킨다면 에이전트는 학습 단계마다 -1, 0, +1 중 한 가지 보상을 받는다. 하지만 팩맨을 학습한다면 학습 단계마다 수백 혹은 그 이상 보상을 획득할 수도 있다. 같은 보상 척도로는 어떤 작업이 더 중요한지 측정할 수 없게 된다는 얘기다.
또 개별 보상 규모가 같더라도 보상 빈도가 다를 수도 있다. 에이전트는 더 큰 보상에 맞춰 집중하는 특성이 있는 만큼 보상 배율과 주파수가 다르면 특정 작업에만 성능이 높아지고 다른 작업에선 성능이 떨어지는 문제가 발생할 수 있다.
이런 문제를 해결하려면 게임마다 얻을 수 있는 보상 규모에 관계없이 에이전트가 게임을 같은 학습 가치로 판단할 수 있도록 게임별 보상 규모를 표준화해야 한다. 그게 바로 팝아트다.
딥마인드에 따르면 최신 강화학습 에이전트에 팝아트를 적용한 결과 57개 이상 다양한 게임을 한 번에 학습할 수 있는 단일 에이전트를 만들어내는 데 성공했다고 한다.
딥러닝은 신경망 가중치를 갱신해 출력을 목표값에 접근하도록 한다. 심층 강화학습에서 신경망을 이용할 때에도 마찬가지다. 따라서 팝아트는 학습 대상의 게임 점수 등 평균값과 보급률을 추정해 점수를 표준화해 변화에 따라서도 안정적인 학습을 가능하게 해준다.
지금까지 강화학습 알고리즘은 보상 클리핑을 이용해 보상 배율 변화 문제를 극복할 수 있도록 하려 해왔다. 큰 점수를 +1, 작은 점수는 -1 등으로 대략적으로 분류해 보상을 표준화하려 한 것이다. 보상 클리핑을 이용하면 에이전트 학습은 간단해지지만 에이전트가 특정 동작을 수행하지 않는 경우가 발생할 수 있다. 전통적인 방식인 보상 클리핑을 통한 멀티태스킹 학습이 최선의 방법은 아니라는 얘기다.
다시 게임으로 예를 들면 팩맨의 게임 목표는 가능한 한 높은 점수를 내는 것이다. 팩맨에서 포인트를 얻는 방법은 2가지다. 하나는 스테이지에 있는 걸 먹거나 다른 하나는 아이템을 먹은 뒤 괴물을 먹는 것. 그냥 일반 아이템을 먹으면 10포인트, 괴물을 먹으면 200∼1,600포인트를 얻는다.
이 때 보상 클리핑을 이용하면 일반 아이템으로 얻은 포인트와 괴물을 먹었을 때 발생하는 포인트 차이를 찾아낼 수 없는 문제가 생긴다. 더 높은 포인트를 얻겠다고 괴물을 먹으려고 하지 않게 된다.
보상 클리핑 대신 팝아트를 적용하면 보상이 표준화되기 때문에 에이전트는 괴물을 먹는 게 중요하다는 걸 인식할 수 있다.
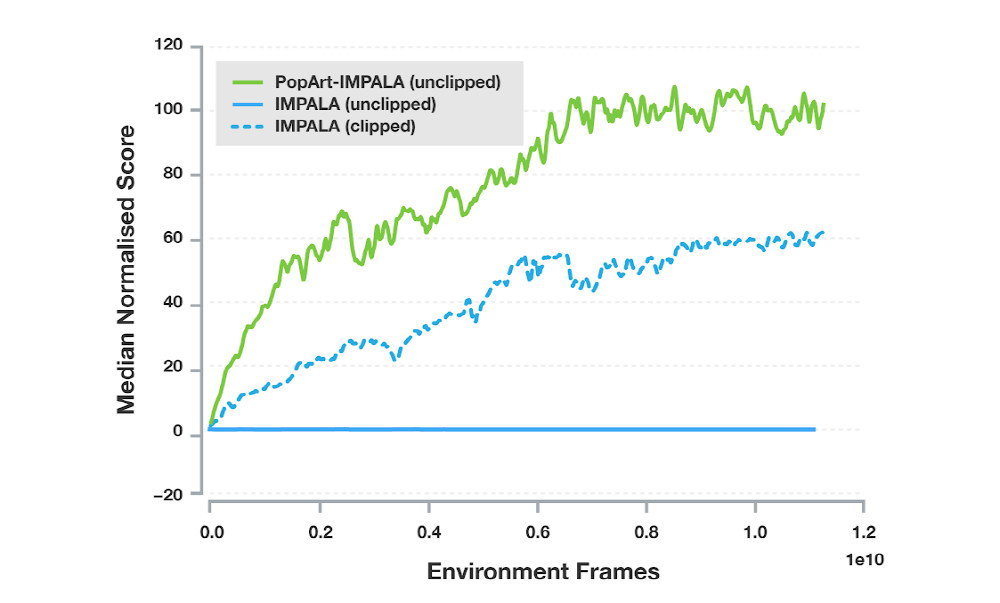
딥마인드가 이용하는 에이전트 중 가장 인기 높은 것 중 하나인 임팔라(IMPALA)에 팝아트를 적용한 결과(위 그래프) 에이전트 성능을 큰 폭으로 개선하는 데 성공했다고 한다. 딥마인드 측은 이런 멀티태스킹 환경에서 단일 에이전트로 높은 성능을 기록한 건 처음이라면서 다양한 보상을 이용해 여러 목적에 맞는 에이전트를 학습시킬 때 팝아트가 큰 힘을 발휘할 것이라고 밝히고 있다.
팝아트의 등장은 갈수록 복잡해지는 인공지능 관련 연구에 큰 도움이 될 것으로 기대된다. 에이전트를 통한 학습은 마치 동물에게 서커스를 배우게 할 때 잘하면 보상(먹잇감)을 주는 것처럼 에이전트에 보상을 주면서 성장시키는 과정을 거친다. 이런 점에서 팝아트 같은 표준화된 보상은 상당한 도움이 될 것으로 보인다. 관련 내용은 이곳에서 확인할 수 있다.