비영리 AI 연구조직인 일루서AI(EleutherAI)가 토론토대학교와 허깅페이스 등과 공동으로 퍼블릭 도메인 및 오픈 라이선스 콘텐츠만으로 구성된 데이터세트인 커먼 파일 v0.1(Common Pile v0.1)을 공개했다. 커먼 파일 v0.1로 훈련된 AI 모델인 Comma v0.1-1T와 Comma v0.1-2T는 저작권으로 보호된 무허가 데이터를 사용해 개발된 모델과 동등한 성능을 발휘했다고 밝혔다.
오픈AI를 포함한 AI 기업은 AI 모델 훈련 방법을 둘러싸고 소송에 휘말리고 있다. AI 훈련에 사용되는 데이터세트는 서적이나 연구 저널 등 저작권으로 보호된 자료를 포함한 웹상 정보를 스크래핑해 구축되는 경우가 대부분. 이 때문에 생성형 AI에는 저작권 침해 위험이 있다는 목소리가 나오고 있다. 일부 AI 기업은 특정 콘텐츠 제공업체와 라이선스 계약을 맺고 있지만 대부분 기업은 저작권으로 보호된 저작물을 허가 없이 학습시킨 경우 미국 법리인 페어유스 원칙에 의해 책임을 면할 수 있다고 주장하고 있다.
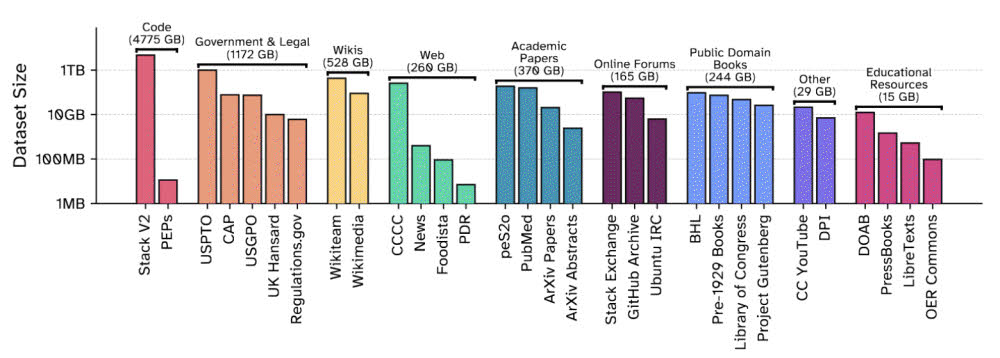
커먼 파일 v0.1은 일루서AI가 2020년 출시한 800GB 데이터세트인 더파일(The Pile) 후속작에 해당한다. 데이터세트는 30종류로 전체 용량은 8TB에 달한다. 내역은 코드(4775GB), 법률 및 정부 문서(1172GB), 위키피디아 등 문장(528GB), 학술논문(370GB), 퍼블릭 도메인 서적(244GB), 기타 온라인 포럼, 유튜브 자막, 교육 리소스 등이다.
일루서AI는 커먼 파일 v0.1이 지향하는 목적과 이념으로 투명성과 과학적 엄밀성 확보, 개방성 추진, 오픈 라이선스 준수를 제시했다. 그 중에서도 오픈 라이선스 준수에 대해서는 오픈 널리지 재단이 정의하는 오픈 라이선스 기준에 의존하고 있으며, 이는 어떤 인물이든 어떤 목적을 위해서든 사용, 연구, 수정, 재배포가 허용되어 있다는 걸 의미한다.
수집하는 데이터가 오픈 라이선스인지 여부는 자동화 도구에만 의존하지 않고 신뢰할 수 있는 정보원 메타데이터나 수동 큐레이션을 통해 확인되고 있다.
일루서AI는 또 커먼 파일로 훈련한 70억 개 매개변수 언어모델인 Comma v0.1이 라이선스가 없는 데이터로 훈련된 주요 모델에 필적하는 성능을 가진다는 점을 보여줬다. Comma v0.1-1T는 1조 개 토큰으로 Comma v0.1-2T는 2조 개 토큰으로 훈련됐다.
일루서AI는 커먼 파일로 학습한 모델은 더파일이나 OSCAR 같은 라이선스가 없는 데이터세트로 학습한 모델과 손색없는 성능이었다면서 다만 대규모 데이터 풀에서 고품질 데이터만을 엄격하게 필터링하는 파인웹(FineWeb)에는 미치지 못한다고 보고했다.
일루서AI는 이 데이터세트를 커먼 파일 v0.1이라고 부르는 건 명확한 의도 표명이라며 이번 출시를 기쁘게 생각하지만 이게 마지막 단계가 아니라 첫 번째 단계라며 더 크고 더 우수한 버전을 구축하고 현재 이용할 수 없는 오픈 라이선스 데이터를 해방시키며 더 많은 걸 일반에 환원하고 싶다고 말했다. 관련 내용은 이곳에서 확인할 수 있다.