메타 기초 인공지능 연구소인 FAIR는 고도의 기계 지능(AMI)을 실현하고 이를 활용해 모든 이들에게 이익이 되는 제품과 혁신을 추진하는 데 중점을 두고 있다. FAIR는 스페인 바스크 인지·뇌·언어 센터와 공동으로 AI가 인간 지능에 대한 이해를 높이고 AMI에 가까워지는 데 도움이 되는 2가지 획기적인 성과를 발표했다.
메타는 뇌 활동에서 이미지와 음성 인식을 해독하는 기존 연구를 바탕으로 비침습적 방법으로 수집한 뇌파에서 문장 생성을 해독하는 연구를 발표했다. 이 연구에서는 뇌 신호만으로 문자 최대 80%를 정확하게 해독하고 완전한 문장을 재구성하는 데 성공했다. 메타가 발표한 또 다른 연구는 AI가 뇌 신호 이해에 도움이 되는 방법을 자세히 설명한 것으로 뇌가 사고를 효과적으로 단어 시퀀스로 변환하는 방법이 해설되어 있다.
매년 수백만 명이 의사소통을 방해할 수 있는 뇌 손상으로 고통 받고 있다. 기존 접근 방식에서는 AI 디코더에 명령 신호를 보내는 신경 보철 장치로 의사소통을 회복할 수 있다는 게 입증됐다. 하지만 정위 뇌파 기록법이나 피질 전기 기록법 등의 침습적 뇌 기록 기술에는 신경외과적 개입이 필요하며 확장이 어렵다. 반면 비침습적 접근 방식의 경우는 기록하는 신호에 대한 노이즈 복잡성으로 인해 제한되는 게 보통이었다.
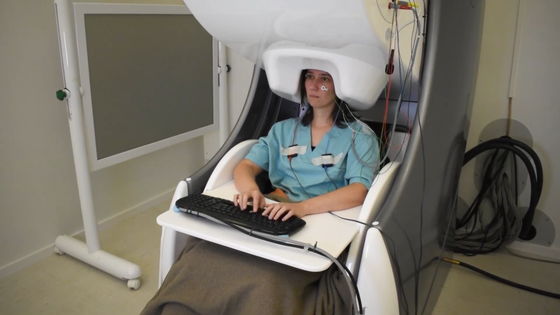
메타가 발표한 첫 번째 연구에서는 신경 활동으로 인해 발생하는 자기장과 전기장을 측정하는 비침습성 장치인 MEG와 EEG를 사용해 건강한 자원봉사자 35명이 문장을 입력하는 모습을 기록했다. 다음으로 뇌 신호만으로 문장을 재구성하기 위해 새로운 AI 모델을 훈련시켰다. 이 AI 모델은 MEG로 기록한 참가자가 문자를 입력할 때의 뇌파에서 입력 문장 최대 80%를 해독하는 데 성공했다. 이는 EEG 기반 뇌파 기반 입력 문장 예측보다 최소 2배 뛰어난 것으로 나타났다.
이 연구는 말하는 능력을 잃은 이들의 의사소통 능력을 회복시키는 데 도움이 되는 비침습적 뇌-컴퓨터 인터페이스 개발에 새로운 길을 열 수 있다. 다만 이 접근 방식을 임상 현장에 적용하려면 몇 가지 중요한 과제가 남아있다. 첫 번째 과제는 디코딩 성능이 아직 불완전하다는 점이며 또 하나는 MEG를 사용하려면 피험자가 자기 차폐된 방에서 가만히 있어야 한다는 점이다. 다시 말해 실용성 면에서 어려움이 있다는 것이다. 그리고 3번째 문제는 실제로 뇌 손상으로 고통 받는 이들에게 어떤 이익을 가져다줄지 탐구하려면 추가 연구가 필요하다는 점이다.
뇌가 사고를 효과적으로 단어 시퀀스로 변환하는 방법에 관한 연구에서는 입과 혀를 움직이면 신경 영상 신호가 크게 손상된다는 단순한 기술적 문제를 안고 있었다. 뇌가 사고를 복잡한 일련의 운동 동작으로 변환하는 구조를 탐구하기 위해 연구팀은 피험자가 문장을 입력하는 동안 AI를 이용해 MEG로 검출한 신호를 해독했다. 매초 뇌 스냅샷 1,000장을 촬영해 사고가 단어·음절·문자로 변환되는 정확한 순간을 특정하는 데 성공했다.
메타는 중요한 건 이 연구를 통해 뇌가 연속되는 말이나 행동을 일관성 있게 동시에 표현하는 방법도 밝혀졌다는 것이라고 기술했다. 언어 신경 코드를 해독하는 건 AI와 신경과학에서 큰 과제 중 하나다. 메타 측은 인간 특유 언어 능력은 지구상 다른 어떤 동물에게도 없는 추론·학습·지식 축적 능력을 인간에게 부여하고 있기 때문에 신경 구조와 계산 원리를 이해하는 건 AMI 개발로 가는 중요한 길이라고 기술했다.
한편 메타는 이런 연구에 대해 신경과학 커뮤니티에서 키워온 긴밀한 협력 관계 없이는 실현할 수 없었을 것이라고 기술했다. 더불어 메타는 추가 연구 지원을 위해 로스차일드 재단 병원에 220만 달러를 기부하기로 했다고도 발표했다. 관련 내용은 이곳에서 확인할 수 있다.
한편 대규모 언어 모델 LLaMA를 개발하는 메타는 2023년 7월 저작권으로 보호된 서적을 사용해 AI를 훈련시켰다는 이유로 제소당했다. 이 재판에서 새롭게 메타가 해적판 전자책 라이브러리인 Z-라이브러리(Z-Library)와 안나아카이브(Anna’s Archive) 등에 저장된 81.7TB 분량 데이터를 사용해 LLaMA 훈련을 진행했다는 증거가 제시됐다.
코미디언이자 작가인 사라 실버만과 작가 크리스토퍼 골든, 리처드 캐드리는 챗GPT와 LLaMA가 불법으로 인터넷상에 유통되고 있는 작품을 데이터세트로 훈련된 것이라고 주장하며 2023년 7월 오픈AI와 메타를 고소했다.
2025년 1월에는 메타의 직원이 해적판 전자책 라이브러리인 LibGen(Library Genesis)을 기반으로 한 데이터세트에서 저작권 정보를 삭제했다는 걸 인정하는 증언이 있었고 공개된 사내 문서에서 메타가 공식적으로 LibGen 사용을 인정했다는 점이 지적됐다.
또 2025년 2월 원고 측은 메타의 불법적인 AI 훈련의 규모는 놀라운 수준이라며 2024년 봄만 해도 메타는 안나아카이브를 통해 여러 해적판 전자책 라이브러리에서 최소 81.7TB 데이터를 획득했다면서 여기에는 Z-라이브러리와 LibGen 내 최소 35.7TB의 데이터도 포함되어 있다고 비판했다. 또 원고 측은 메타가 LibGen에서 입수한 데이터가 80.6TB에 달한다고 지적했다.
이제까지의 재판에서 메타는 일관되게 LibGen을 사용한 AI 훈련은 공정 이용이라고 주장하고 있다. 하지만 메타는 데이터세트를 다운로드할 때 페이스북 인프라를 사용하지 않음으로써 데이터 획득자가 메타라는 사실이 밝혀질 리스크를 회피했다는 사실이 공개된 이메일에서 드러났다. 이에 원고 측은 메타는 해적판 전자책 라이브러리에서의 데이터 수집 행위가 불법이라는 걸 인식하고 있었다고 주장했다.
반면 메타는 원고는 서적 일부가 실제로 제3자에 의해 메타에서 해적판 전자책 라이브러리를 통해 다운로드됐다는 사례를 단 한 건도 보고하지 않았다며 더군다나 원고 측 서적이 어떤 형태로든 메타에 의해 배포됐다고도 주장하지 않았다며 원고 측 주장 기각을 요구하고 있다. 관련 내용은 이곳에서 확인할 수 있다.