애플은 12월 18일 엔비디아와의 공동 연구를 통해 대규모 언어 모델(LLM) 추론 처리 속도를 가속화한 연구 성과를 발표했다. 애플이 독자 개발한 리드래프터(ReDrafter) 기술을 엔비디아 GPU용 추론 프레임워크인 TensorRT-LLM에 통합해 처리 속도를 최대 2.7배 향상시키고 소비 전력 및 GPU 사용량을 줄이는 데 성공했다고 밝혔다.
애플은 지난 3월 리드래프터라는 새로운 추론 가속화 기술을 발표하고 오픈소스로 공개했다. 이 기술은 2가지 기법을 결합해 LLM 텍스트 생성 속도를 크게 높인다. 첫 번째는 빔 서치(Beam Search)로 최적의 출력 시퀀스를 찾기 위한 탐색 알고리즘이다. 2번째는 다이내믹 트리 어텐션(Dynamic Tree Attention)으로 선택지를 효율적으로 처리하는 방식이다.
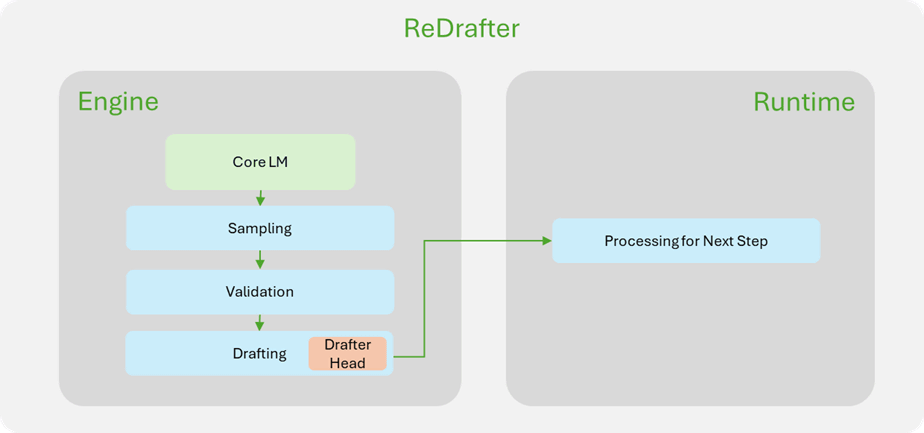
리드래프터 기술 핵심은 추론 디코딩(Inference Decoding) 과정 효율화다. 기존 LLM은 텍스트를 생성할 때 하나씩 순차적으로 토큰을 처리해야 했으나 리드래프터는 RNN 기반 드래프트 모델을 사용해 다음에 나올 가능성이 높은 토큰을 예측하고 여러 후보를 동시에 평가해 속도를 높였다.
애플은 리드래프터를 통해 생성 단계 한 번으로 최대 3.5개 토큰을 처리할 수 있어 기존 기술 대비 뛰어난 성능을 달성했다고 주장한다. 애플은 이번 발표에서는 엔비디아와 협력해 GPU에 적용 가능한 형태로 기술을 실용화했다고 밝혔다. 엔비디아 역할은 문맥 처리 단계와 생성 단계의 요청을 효율적으로 관리하는 인프라이트 배칭(IFB), 토큰 검증 및 경로 수락을 엔진 내부에서 처리해 오버헤드를 줄여주는 엔진 내부 최적화다.
엔비디아 H100 GPU를 사용한 수백억 개 파라미터를 가진 모델에서 2.7배 속도 향상이 확인됐다. 그 중에서도 코드 보완과 같은 특정 작업이나 소규모 배치 처리 및 저트래픽 시나리오에서 높은 효율성을 발휘했다.
애플 기계 학습 연구팀은 이번 가속화 기술을 통해 사용자 대기 시간이 크게 줄어드는 동시에 GPU 사용량 및 소비 전력을 절감할 수 있었다고 밝혔다. 이는 대규모 언어 모델 실용화에 중요한 진전을 가져올 것으로 평가된다. 관련 내용은 이곳에서 확인할 수 있다.