
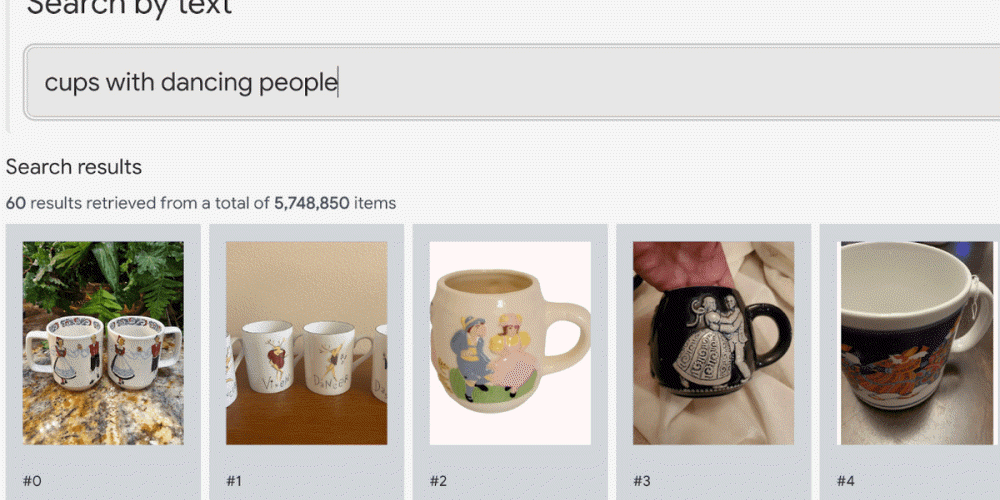
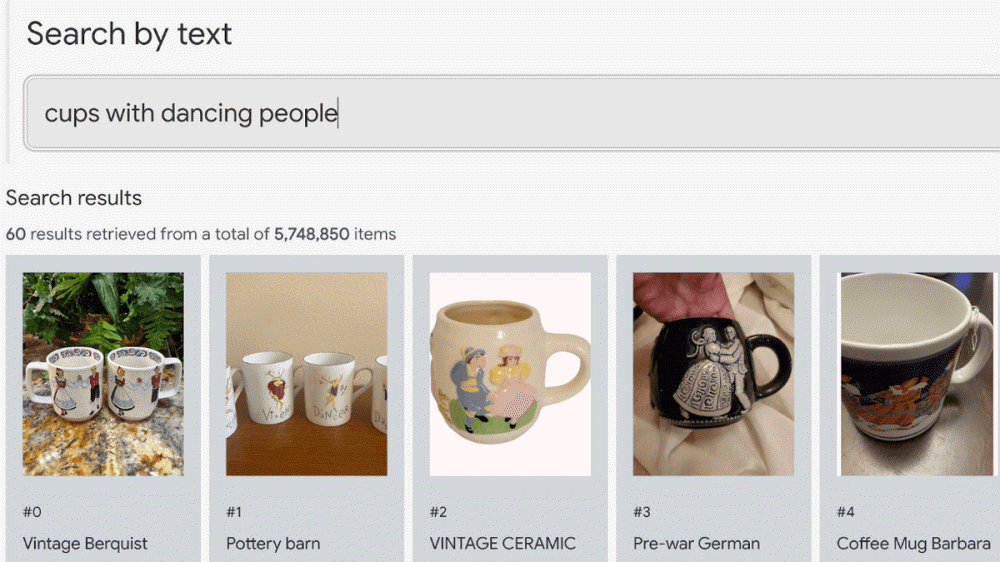
구글이 대규모 언어 모델 LLM에 시각을 갖게 한 대규모 시각 모델 VLM(vision language model) 데모를 공개하는 동시에 VLM 구조에 대한 해설 기사를 올렸다.
VLM 데모는 사이트에도 공개되어 있다. 직접 텍스트를 입력할 수도 있지만 데모가 제안하는 걸 클릭하면 검색란에 문자가 자동으로 입력되며 곧바로 검색 결과가 나온다. 구글에 따르면 이 검색은 타이틀, 설명, 태그 등을 사용하지 않고 이미지를 AI가 분석하는 것만으로 성립한 것이라고 한다. 이 때문에 검색성이 낮을 것 같은 문장에서도 적절한 상품을 검색할 수 있다.
문자 인식도 할 수 있다. 심층 학습 모델을 이용하면 텍스트, 이미지, 음성 등 의미에 따른 공간 배치가 가능하다. 예를 들어 이미지라면 각각 이미지가 인간, 음식, 장난감 등으로 분석되어 해당 성분으로 이뤄진 임베디드 공간 위에 배치되게 된다. 유사 성분을 가진 이미지는 임베디드 공간에서 가까운 위치에 배치된다. 이 구조를 이용하면 이미지에서 이미지를 검색하는 시스템을 구축할 수 있다.
심층 학습 모델에선 텍스트와 이미지 쌍을 활용해 학습할 수도 있다. 구글은 이미지를 임베디드 공간에 배치하는 모델, 텍스트를 임베디드 공간에 배치하는 모델, 양자 공간 관계를 학습하는 모델 3가지 모델을 이용해 학습을 실시했다고 한다. 대규모 언어 모델에 시각을 부여하는 것과 같은 것이라는 설명이다. 이렇게 하면 이미지와 텍스트를 포함한 공간에 배치할 수 있다.
이 공간을 이용하면 텍스트에서 이미지를 검색하거나 반대로 이미지에서 텍스트를 검색할 수 있다. 구글은 또 노믹AI(Nomic AI)와 협력해 시각화 데모를 구축했다. 이를 통해 모델이 이미지를 이해하는 방법을 엿볼 수 있다.
구글 측은 VLM 응용례로 인터넷 경매에 출품할 때 상품 이미지를 올리는 것만으로 타이틀이나 설명이 자동 입력되거나 여러 텍스트를 이용해 다수 카메라를 효율적으로 관리하는 예시를 밝히고 있다. 그 밖에 자율주행 등으로 기계학습을 실시할 때 데이터 정리 효율적 실시도 가능하다.
텍스트와 이미지를 동시에 검색할 수 있는 멀티모달 검색 사용을 생각하는 사람을 위한 서비스도 소개하고 있다. 웹사이트와 PDF 파일을 검색할 때 좋을 기능(Gen App Builder Enterprise Search), 대량 이미지와 영상에 대한 의미론적 검색을 수행하거나 유사성 검색을 할 때 좋은 기능(Vertex AI Vision Warehouse), 데이터가 표 형태로 정리되어 있는 경우에는 엔터프라이즈 검색에 몰티모달을 포함한 기능(Vertex AI Matching Engine)을 이용하는 게 좋다는 설명이다. 관련 내용은 이곳에서 확인할 수 있다.



















