

번역의 미래는 인공지능? 100개가 넘는 언어를 대상으로 번역 서비스를 실시하고 있는 구글은 서비스 10주년을 맞은 지난 2016년 자연스러운 번역을 위해 인공지능을 활용한 GNMT(Google Neural Machine Translation)라는 시스템을 발표한 바 있다.
이 기능은 구글 번역이 당시까지 쓰던 문구를 기반으로 한 PBMT라는 시스템을 대신한 것. 단어와 구문마다 기계적으로 문장을 번역하는 게 아니라 문장 전체를 하나의 번역 단위로 파악할 수 있게 해준다. 이렇게 문장 전체를 번역 단위로 파악하면 공학적 설계에서 선택이 쉬워진다는 것 외에 번역 정확도와 속도를 높일 수 있다는 장점이 있다. 당시 구글이 발표한 바에 따르면 GNMT를 이용하면 번역 오류를 55∼85%까지 줄일 수 있다고 한다. 구글은 또 GNMT를 이용하면 일부지만 인간 수준 번역이 가능하게 된다고 덧붙이기도 했다.
또 구글이 이런 예시로 보여줬던 건 중국어였다. 중국에서 영어 번역은 하루 1,800만 건에 달한다고 한다. 그런데 마이크로소프트가 3월 14일(현지시간) 자체 개발한 인공지능을 이용한 번역 기술을 통해 중국어를 영어로 번역하는 기술 수준이 인간 번역과 같은 동등한 수준에 도달했다고 밝혀 눈길을 끈다(참고 링크 : https://blogs.microsoft.com/ai/machine-translation-news-test-set-human-parity/).
이에 따르면 마이크로소프트가 개발한 시스템의 번역 품질을 확인하기 위해 뉴스테스트2017(newstest2017)이라는 테스트를 통해 평가를 받았고 지난 2017년 가을 열린 연구자 회의인 WMT17에서 발표된 바 있다. 마이크로소프트 측은 또 번역 결과를 인간 번역과 비교하기 위해 외부 번역 평가자를 써서 내용 비교를 실시해 인공지능 번역이 정확성과 품질 면에서 인간이 한 것에 필적하는 수준에 있는 것으로 확인했다고 밝히고 있다.
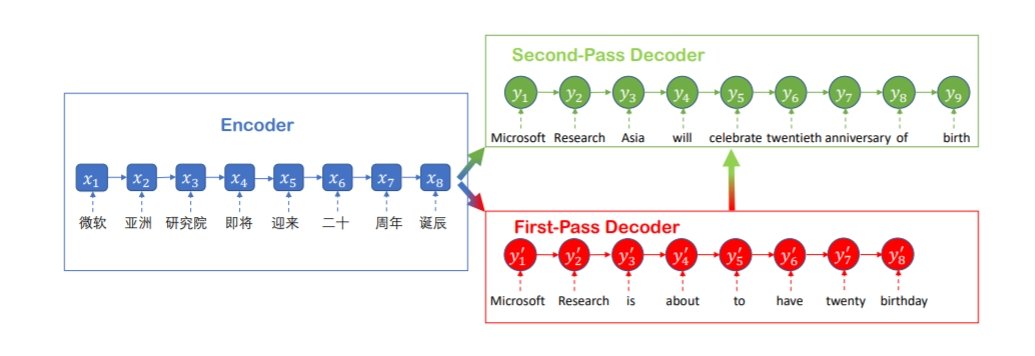
마이크로소프트 측은 이번 결과에 대해 기계 번역이 인간의 것과 같은 품질에 도달하는 건 번역 입장에서 가장 난이도가 높은 언어 처리 작업사에 큰 이정표가 될 것이라고 밝히고 있다.
다만 아직까지 실제 AI 번역이 인간과 같은 수준까지 실현되려면 아직까지 남은 과제가 많다. 마이크로소프트 측 역시 실시간 뉴스 번역 기술 등에는 아직까지 남은 부분이 많다고 밝히고 있다. 일반 뉴스에서도 번역 품질이 같은 수준이 되려면 노력이 더 필요하다. 더 자연스럽게 읽고 듣기가 가능한 번역을 여러 언어로 제공해야 하는데 구조가 복잡한 언어나 전문 용어까지 인간과 같은 번역 품질을 실현하려면 연구가 더 필요한 것.
이미 인공지능이 진화를 거듭하면서 기계가 인간을 대신해서 노동을 할 것이라는 예측이 나오기도 하지만 과학자를 대상으로 지난 2015년 조사한 예측 결과가 참고가 될 만하다. 학술회의 등에 AI 관련 발표를 한 과학자 352명을 대상으로 조사한 결과 중에는 2024년 언어 통역을 할 수 있는 기계가 나온다는 것도 포함되어 있다. 조사에선 기계가 인간의 손을 빌리지 않고도 모든 작업을 인간보다 더 잘 처리할 수 있는 걸 HLMI(High-level machine intelligence)로 정의했다. 조사 결과 이런 HLMI는 앞으로 45년 안에 나올 확률은 50%, 9년 이내는 10%를 나타냈다. 다른 결과를 보면 2027년에는 트럭 운전을 할 수 있는 기계가 나오고 2031년에는 영업 사원을 대체하게 되며 2053년에는 외과 의사로 일할 수 있는 기계가 등장할 것으로 예상하고 있다.
어쨌든 이런 예상 결과를 봐도 앞으로 10년 안팎이면 아마추어 번역가를 뛰어 넘는 수준으로 인공지능이 번역을 할 수 있는 시대가 열릴 것으로 전망해볼 수 있겠다. 다만 마이크로소프트도 넘어야 할 산이 많다고 밝혔듯 아직까지 신경망을 통해 번역률을 높이려면 수백만 개에 달하는 글을 번역한 학습 데이터가 필요하다. 구글의 경우 지난해 이런 번역에 필요한 문서 없이 신경망이 번역 관련 학습을 습득할 수 있는 새로운 기술을 발표한 바 있다.
기존 인공지능 번역은 데이터 역할을 하는 문서가 많아야 한다. 이런 이유로 영어나 불어 등 언어별 문서가 많은 쪽이 번역률도 더 높아진다. 이에 비해 마이너 언어라면 번역 정확도는 떨어질 수밖에 없다.
지금까지 기계학습이 이렇게 인간이 먼저 인공지능에 알려주는 가르침이 필요했다면 구글이 새로 발표한 방식은 다르다. 인간이 인공지능에게 가르칠 수 없고 인공지능이 사전을 만든다. 책상과 의자라는 단어가 함께 자주 쓰인다는 점 등 언어마다 유사점이 존재하는데 이런 공통점을 기초로 매핑을 하면서 사전 만들기를 할 수 있다는 것이다. 이런 다음 여러 번 학습과 지도를 거듭하면서 번역용 사전이 완성되는 것이다.
이와 관련한 기술 연구도 몇 가지 발표된 바 있다. 이런 연구는 역번역이나 이 과정에서 노이즈를 제거하는 걸 다룬다. 역번역이란 일단 다른 언어로 대충 번역한 문장을 원래 언어로 다시 번역한다. 이 때 신경망은 역번역한 문서와 원문이 일치하지 않으면 조정 과정을 거친다. 이런 방식을 이용하면 같은 문서로 2가지 언어를 확인할 수 있게 된다.
노이즈 제거란 번역과 비슷하지만 역번역을 할 때 단어를 빼거나 재구성할 때 원래 문장을 재현하려고 한다. 이런 역번역과 노이즈 제거 과정을 거치면 신경망은 문자 구조를 더 깊은 곳까지 배울 수 있게 된다는 것이다.
물론 아직까지 이런 기술을 쓴다고 해도 번역 정확도가 구글 번역보다 못하다고 한다. 하지만 이런 기술은 풍부한 데이터가 없더라도 장기적으로 번역률을 높이는 데 기여할 가능성이 있다고 할 수 있다.
사실 이런 번역과 역번역 사이에서 재미있는 결과가 발표된 적이 있다. 구글이 GNMT를 도입하는 등 구글 번역에 인공지능을 도입한 이후 번역 과정에서 중간 언어같은 걸 자체적으로 내부에 만들어서 아직 학습하지 않은 언어 조합을 통해 일정 수준을 번역하는 능력인 제로샷 번역(Zero-Shot Translation)이 가능하다는 내용을 발표한 것.
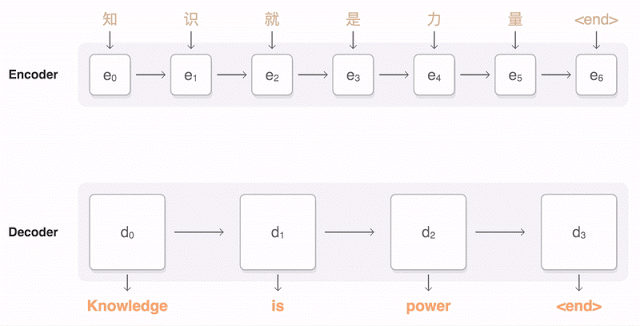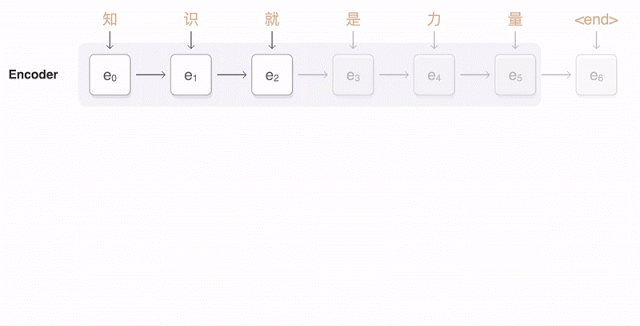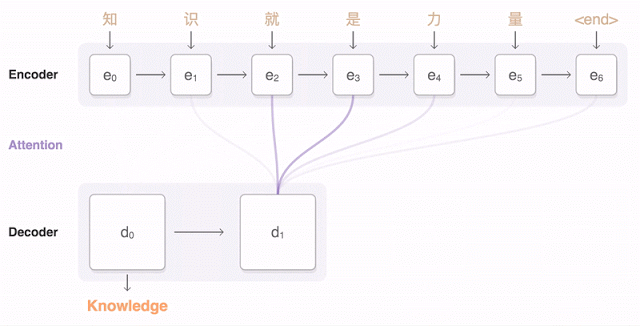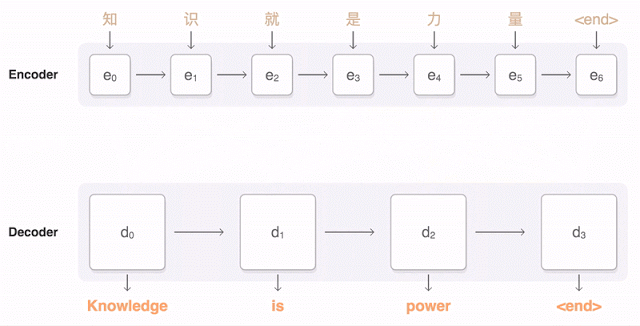
GNMT는 학습을 통해 코퍼스(corpus) 그러니까 언어학에서 자연 언어 처리 연구를 위해 자연어 문장을 구조화해 대규모로 집적한 구조화한 언어 정보를 바탕으로 번역을 학습한다. 이를 통해 여러 언어를 자연스럽게 번역하게 된다. 이런 학습을 할 때 한 언어에서 다른 언어로 번역되는 게 학습되지만 아직 학습하지 않은 언어 조합이라면 아무런 준비도 되어 있지 않은 셈이다.
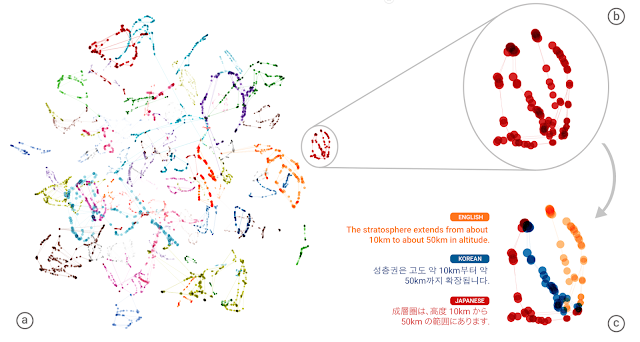
하지만 구글이 발표한 바에 따르면 인공지능은 학습 과정에서 독자적으로 언어를 처리하기 위한 중간 언어(interlingua)를 만들어낸다는 것이다. 중간 언어는 단어끼리 1:1 매칭이 되는 건 아니고 추상적인 개념에 가까운 정보를 유지한다. 예를 들면 이런 식이다. 영어와 한국어 번역 학습을 시킨다. 영어를 한국어로, 한국어를 영어로 바꾸는 학습을 했다면 그런 다음 영어를 일본어, 다시 역번역을 하는 번역하는 학습을 한다. 이렇게 하면 일본어와 한국어 번역도 어느 정도 할 수 있게 된다는 것이다. 정확도는 떨어져도 나름 번역률을 보인다는 것이다. 일본어와 한국어를 번역하는 학습을 하지 않았더라도 중간 언어 덕에 제로샷 번역이 가능해진다는 것이다. 이런 점은 GNMT 같은 신경망을 도입한 인공지능 번역이 단어나 문장이 가진 의미나 개념을 비슷한 위치에 두고 인식하고 있다는 점을 알 수 있게 해준다. 인공지능의 번역 능력이 지금까지보다 훨씬 더 인간의 뇌에 가까운 구조가 되어가고 있다고 할 수 있는 것.
구글은 또 지난해 언어 모델링이나 기계 번역, 질의응답 등 언어 이해에 뛰어난 접근 방법으로 쓰이고 있는 순환 신경망(RNN: Recurrent Neural Network)보다 언어 이해 작업이 뛰어나다며 새로운 신경망 구조인 트랜스포머(Transformer)도 개발했다고 밝힌 바 있다.
RNN부터 먼저 설명하자면 이미지 인식이나 음성 인식 같은 것에 쓰이는 일반적인 기술은 심층신경망(Deep Neural Network)이다. 특정 시각에서의 추정을 할 수는 있지만 동영상에서 상태를 인식하거나 음성의 의미를 이해하려면 이걸로는 부족하다. 이런 이유로 전후 시계열 정보를 처리할 수 있는 RNN이 개발된 것이다.
RNN은 이전 시간대 중간대를 다음 시간 입력과 함께 학습에 이용한다. 시계열 정보를 고려한 네트워크 구조인 것. RNN은 시계열 정보를 유지한 네트워크, DNN을 시간대로 연결한 큰 네트워크라고 할 수 있다. RNN은 언어 예측 같은 것에 쓸 수 있는 이유도 여기에 있다.

구글이 언어 이해 작업에 더 뛰어나다고 밝힌 신경망 아키텍처인 트랜스포머는 학습에 필요한 계산량이 다른 신경망보다 압도적으로 적다고 한다. 구글에 따르면 계산 성능이나 번역 정밀도를 높일 수 있는 점 외에도 트랜스포머는 특정 단어를 처리하거나 번역할 때 관련 문장의 다른 부분을 시각화, 정보가 어떻게 이동하는지에 대한 통찰력을 볼 수 있다는 것이라고 한다. 트랜스포머를 이용한 개발은 텐서플로우 라이브러리를 이용하며 몇 가지 명령을 호출하면 트랜스포머 네트워크를 학습 환경으로 갖출 수 있다고 한다.
이렇게 인공지능 번역을 둘러싼 기술 개발이 한창이다. 이번 마이크로소프트가 밝힌 특정 언어이긴 하나 기계 번역이 인간이 번역한 것과 같은 품질을 보였다는 건 시작일 뿐일 수는 있지만 상당한 의미가 있다고 할 수 있다. 전문가의 예상처럼 앞으로 10년 안에 인공지능 번역 시대가 열려 언어의 벽이 허물어질지 관심이 모아지는 대목이다.






















