구글은 연례 개발자 이벤트인 구글 I/O 2025에서 자사 AI 모델인 구글 제미나이(Google Gemini)를 사용할 수 있는 새로운 구독 서비스 플랜으로 월 249.99달러인 구글 AI 울트라(Google AI Ultra)를 발표했다. 이 서비스는 먼저 미국에서 제공되며 곧 다른 국가 및 지역으로도 확대될 예정이다.
구글은 구글 AI 울트라를 구글 AI 고성능 모델과 프리미엄 기능에 접근할 수 있는 가장 제한이 느슨한 플랜이라고 설명했다.
현재 구글 AI 울트라 플랜 구성을 보면 먼저 제미나이. 구글 AI 울트라에서는 딥리서치(Deep Research) 기능 사용 제한이 가장 적고 베오 2를 통한 동영상 생성, 베오 3 모델에 대한 조기 접근이 가능하다. 이 플랜은 코딩, 학술 연구, 창작 활동 등을 위해 설계됐으며 6월 중에는 제미나이 2.5 프로 강화 추론 모드인 딥씽크(Deep Think)에도 접근할 수 있게 될 예정이다.
그 뿐 아니라 구글 AI 울트라를 통해 구글 I/O 2025에서 발표된 AI 영화 제작 도구인 플로우(Flow)에 접근할 수 있다. 1080p 해상도 동영상 생성, 고급 카메라 제어, 베오 3 조기 접근 기능을 통해 플로우를 최대한 활용할 수 있게 된다.
다음으로 위스크(Whisk). 위스크는 이미지를 프롬프트로 사용해 아이디어를 시각화해주는 도구다. 구글 AI 울트라에서는 베오 2로 생성된 영상을 쇼츠 형태 영상으로 변환할 수 있는 위스크 애니메이트(Whisk Animate)를 최대한 활용할 수 있다.
이어 노트북LM(Notebook LM)은 2025년 후반 가장 느슨한 사용 제한과 강화된 모델 기능이 구글 AI 울트라에 제공될 예정이다.
다음은 제미나이와 구글 서비스 통합. G메일, 구글 문서, 구글 크롬에서 구글 제미나이를 직접 접근해 사용할 수 있게 된다. 이를 통해 일상적인 작업을 수행하는 건 물론 크롬에 표시된 페이지 내용을 인식해 작업에 반영하는 것도 가능해진다.
또 프로젝트 마리너(Project Mariner)는 현재 개발 중인 AI 에이전트로 정보 검색부터 예약, 생필품 구매까지 대시보드 하나에서 최대 10개 작업을 동시에 수행할 수 있다.
유튜브 유료 서비스인 유튜브 프리미엄도 이용 가능하다. 이를 통해 광고 없이 유튜브를 시청하고 오프라인 재생 및 백그라운드 재생 기능을 사용할 수 있으며 유튜브 뮤직도 광고 없이 이용할 수 있다.
또 구글 포토, G메일, 구글 드라이브 등 구글 서비스에서 사용할 수 있는 저장 용량으로 30TB가 제공된다.
기존 유료 구글 AI는 구글 AI 울트라라는 명칭으로 제공될 예정이다. 구글 AI 울트라는 먼저 미국에서 출시된 뒤 순차적으로 다른 국가 및 지역으로 확대된다. 구글 AI 울트라 월 구독료는 249.99달러지만, 첫 이용 시에는 처음 3개월 동안 50% 할인된 124.99달러로 이용할 수 있다. 또 학생을 대상으로 구글 AI 울트라를 1년간 무료로 이용할 수 있는 서비스가 미국 뿐 아니라 영국, 일본, 브라질, 인도네시아에서도 제공될 예정이라고 발표됐다.
◇ 크롬‧G메일에도 ‘AI 인사이드’=구글은 또 PC 버전 구글 크롬에 제미나이를 통합해 새로운 페이지를 열지 않고도 브라우저에서 직접 AI 챗봇에 접근할 수 있게 한다고 발표했다.
구글랩 및 제미나이 담당인 조쉬 우드워드 부사장은 제미나이는 PC에서 인터넷을 탐색할 때 AI 어시스턴트가 된다며 놀라운 점은 이를 사용하면 현재 표시하고 있는 페이지 컨텍스트를 자동으로 이해해 준다는 것이라고 말했다.
제미나이 인 크롬(Gemini in Chrome)이 활성화되면 상단 바나 시스템 트레이 제미나이 아이콘 또는 크롬 키보드 단축키로 제미나이를 열고 텍스트 박스에 질문을 입력해 제미나이와 대화할 수 있다. 제미나이 라이브를 실행해 음성 대화로 제미나이를 사용할 수도 있다.
구글 측은 향후 제미나이에 여러 탭에 걸친 처리를 수행하게 하거나 사용자를 대신해 웹사이트를 조작하게 하거나 작업을 자동화할 수 있다고 말했다.
제미나이 인 크롬은은 크롬 언어 설정을 영어로 해놓은 미국 윈도 및 맥OS 사용자를 대상으로 출시가 시작됐으며 사용하려면 구글 AI 프로 또는 새롭게 발표된 구글 AI 울트라 구독 플랜에 가입해야 한다. 관련 내용은 이곳에서 확인할 수 있다.
구글은 크롬 뿐 아니라 G메일에도 AI로 답장을 생성해주는 개인화 스마트 답장 기능, 제미나이로 받은 편지함 정리 기능 등을 추가한다고 발표했다.
G메일에는 2016년부터 스마트 작성 기능이 탑재되어 메일을 쉽게 작성할 수 있게 됐다. 개인화된 스마트 답장은 한 걸음 더 나아간 기능. 답장을 어떻게 해야 할지에 대한 제안을 문체나 상대방이 보낸 메일, 구글 드라이브내 파일을 참고하는 등 적절하고 정확한 답장안이 작성되어 필요한 부분만 수정해 전송할 수 있다.

새롭게 G메일에서 직접 일정 예약하기 기능도 추가된다. 앞서와 마찬가지로 답장을 작성할 때 메일 작성 메뉴 내에 캘린더 아이콘이 나타나고 클릭하면 예약 페이지 삽입 등 메뉴가 나타나면 기능을 이용할 수 있다.
더 나아가 단일 명령으로 받은 편지함 정리하기 기능도 생긴다. 받은 편지함 오른쪽에 표시된 제미나이 프롬프트 입력 양식에 지난달 예약 확인 메일을 모두 보관처리라고 입력하면 제미나이가 받은 편지함 내 검색을 해 한꺼번에 보관 처리할 수 있다.
개인화된 스마트 답장은 2025년 하반기, G메일에서 직접 예약과 받은 편지함 정리는 다음 분기(7~9월)에 탑재 예정이라고 한다. 관련 내용은 이곳에서 확인할 수 있다.
◇ 스마트폰‧글라스‧3D 영상 통화까지=구글은 이번 행사에서 스마트폰 최적화 기술을 도입한 오픈소스 AI 모델인 젬마 3n(Gemma 3n) 얼리 프리뷰 버전을 공개했다. 이미 안드로이드 스마트폰에서 쉽게 시험해볼 수 있다.

젬마 3n은 스마트폰이나 태블릿 등에서 로컬 동작시키는 걸 염두에 두고 개발된 AI 모델, 메모리 사용량을 대폭 줄일 수 있는 PLE(Per-Layer Embeddings)라는 기술을 채택하고 있다. 젬마 3n 파라미터 수는 5B와 8B 2가지 종류로 젬마 3n 5B 모델 메모리 사용량은 일반 2B 모델과 동등하며 젬마 3n 8B 모델의 메모리 사용량은 일반적인 4B 모델과 같다.
챗AI 성능을 인간에게 평가받는 테스트(Chatbot Arena)에서 젬마 3n은 GPT-4.1 나노나 Llama-4-Maverick-17B-128E-Instruct를 넘는 점수를 기록했다.
한편 젬마 3n에 채택된 메모리 사용량 절감 기술은 2025년 후반 등장 예정인 차세대 제미나이 나노에도 채택될 예정이다. 관련 내용은 이곳에서 확인할 수 있다.
AI 확장은 스마트폰에만 머물지 않는다. 구글은 안드로이드 XR을 지원하는 스마트 글라스인 프로젝트 아우라(Project Aura)를 발표했다. 프로젝트 아우라는 AR 글라스를 개발하는 XREAL과 공동 개발한 경량 스마트 글라스로 디스플레이 투영과 구글 AI 챗봇 제미나이를 탑재하고 있다.

구글은 2024년 12월 XR용 OS인 안드로이드 XR을 발표했다. 안드로이드 XR은 삼성전자와 공동으로 개발된 OS로 동시에 발표된 개발 키트 안드로이드 XR SDK는 기존 안드로이드 앱 개발 환경을 기반으로 구축된 게 특징이다.
이번 구글 I/O에서는 이런 안드로이드 XR을 탑재한 스마트 글라스에 대해 XREAL이 프로젝트 아우라라는 안드로이드 XR 대응 스마트 글라스를 제조한다고 발표한 것. 프로젝트 아우라는 경량이며 유선 연결식, 광학 시스루(OST)라는 디스플레이 방식을 채택한 게 특징이다. 퀄컴 스냅드래곤 XR 칩셋을 탑재하고 투명한 디스플레이에 특수 광학 소자를 사용해 디지털 콘텐츠가 투영된다. 또 제미나이 AI가 통합되어 있어 지능형 어시스턴트 기능을 제공한다.
구글은 안드로이드 XR 대응 스마트 글라스의 기능성에 대해 스마트폰과 연계해 작동하며 주머니에 손을 넣지 않고도 앱에 접근할 수 있게 된다고 말했다. 구글 I/O에서는 안드로이드 XR 대응 스마트 글라스로 할 수 있는 것으로 다른 언어로 대화할 때 실시간으로 번역을 표시하는 기능이 제시됐다. 또 외출 중 정보를 얻거나 메시지를 전송할 수 있다. 주변 장소까지의 경로를 표시하는 내비게이션 기능도 사용 가능하다.
Hello from Google IO!
— XREAL
This photo was taken using our new XREAL Eye camera with our new XREAL One Pro AR glasses. pic.twitter.com/woqmwDbxEp(@XREAL_Global) May 20, 2025
이미 안드로이드 XR 대응 스마트 글라스 프로토타입을 착용한 리뷰가 해외 미디어에서도 공개됐다. 이에 따르면 프로토타입은 오른쪽 렌즈에만 디스플레이가 탑재되어 있었지만 위화감은 그다지 없었다며 착용감은 편안했고 이론상으로는 하루 종일 착용해도 불만이 없을 것이라고 평가했다.
구글은 자사는 이 기술을 실현하기 위해 브랜드, 파트너와 협력하고 있다며 워비파커(Warby Parker)와 젠틀 몬스터(Gentle Monster)라는 두 패션 브랜드와의 제휴를 발표했다. 워비파커는 적정한 가격에 유행 디자인을 갖춘 직판 브랜드이며 젠틀 몬스터는 에지 있는 디자인이 특징인 브랜드다. 구글은 워비파커와의 제휴 일환으로 스마트 글라스 제조 개발과 상품화에 최대 1억 5,000만 달러 투자를 밝혔다.
구글은 또 삼성전자과의 파트너십을 헤드셋을 넘어 글라스로 확장하고 있다고 언급했다. 삼성전자는 안드로이드 XR 대응 헤드셋 프로젝트 무한(Project Moohan)을 2025년 중 출시할 예정이지만 이에 더해 삼성전자도 안드로이드 XR 대응 스마트 글라스를 개발할 예정이다.
또 하드웨어 측면 발전과 병행해 개발자 생태계 구축도 진행되고 있다. 구글은 개발자를 위한 다양한 리소스를 제공하며 안드로이드 XR용 애플리케이션 개발을 촉진하고 있다. 구글 I/O에서는 안드로이드 XR SDK Developer Preview 2가 발표되어, 입체 동영상 재생 강화, Jetpack Compose for XR, Material Design for XR, ARCore for Jetpack XR 개선, 유니티 연계 강화, Firebase AI Logic 통합 등이 발표됐다. 안드로이드 XR 대응 앱 개발자는 프로젝트 아우라로의 앱 이전을 쉽게 할 수 있다고 한다.
한편 프로젝트 아우라 가격이나 출시일 등은 아직 밝혀지지 않았다. 자세한 내용은 6월 개최되는 세계 최대급 XR 관련 이벤트 AWE USA 2025에서 발표될 예정이며 올해 안에 추가 정보가 공개될 예정이다. 관련 내용은 이곳에서 확인할 수 있다.

구글은 그 뿐 아니라 지금까지 마법의 거울 등으로 표현하며 개발해온 프로젝트 스타라인(Project Starline)을 새로운 3D 비디오 통신 플랫폼 구글 빔(Google Beam)으로 공개했다. 프로젝트 스타라인은 2021년 처음 발표됐다. 비디오 통화 도구는 지금까지도 다양하게 존재했지만 프로젝트 스타라인은 영상이 2D가 아닌 3D라는 점을 통해 마치 얼굴을 맞대고 있는 것처럼 커뮤니케이션할 수 있는 점을 판매 포인트로 삼았다. 2024년에는 프로젝트 스타라인을 전자기기 제조사 HP와 함께 2025년 출시할 예정이라는 게 밝혀졌다.
이어 이번 구글 I/O 2025 행사에서 프로젝트 스타라인이 구글 빔으로 진화했다는 게 발표된 것. 구글 빔은 디스플레이와 여러 카메라로 구성되어 있으며 일반적인 2D 영상을 실시간으로 3D 체험으로 변환한다. 또 목소리 톤과 표현을 유지하면서 대화 내용을 번역할 수 있어 거리나 언어 장벽에 관계없이 원활하게 커뮤니케이션할 수 있게 된다고 한다.
줌, HP와의 파트너십은 계속되고 있으며 앞으로 몇 주 안에 HP에 첫 번째 구글 빔 단말기가 제공되고 올 하반기에는 일부 고객을 대상으로 제공도 시작될 예정이다. 관련 내용은 이곳에서 확인할 수 있다.
◇ 베오3‧이매진4부터 AI 영화 제작 도구까지=구글은 또 동영상 생성 모델 베오 3를 발표했다. 최대 4K 해상도 동영상을 제작할 수 있었던 기존 모델인 베오2 품질을 향상시켰을 뿐 아니라 구글 동영상 생성 AI로서는 처음으로 음성 포함 동영상 생성이 가능해졌다.
사람 목소리, 도심 교통 소리, 공원 새소리, 애니메이션 풍 캐릭터 간 대화 등도 생성할 수 있다. 지금까지 대부분 동영상 생성 모델은 무음 영상만을 생성할 수 있었던 만큼 구글은 베오3 발표에 즈음해 비디오 생성 무음 시대와 작별하자며 성능을 강조했다.
Say goodbye to the silent era of video generation: Introducing Veo 3 — with native audio generation.
— Google (@Google) May 20, 2025
Quality is up from Veo 2, and now you can add dialogue between characters, sound effects and background noise.
Veo 3 is available now in the @GeminiApp for Google AI Ultra… pic.twitter.com/7rcXeBslyU

종이가 스치는 소리, 역동적인 효과음 등 다양한 소리를 포함한 동영상을 생성할 수 있다. 베오3는 텍스트나 이미지로 프롬프트를 입력받아 현실 세계 물리 법칙을 반영하며 정밀한 립싱크를 구현할 수 있다고 한다. 이해력도 뛰어나 짧은 스토리만 제공해도 내용을 선명하게 표현한 영상을 만들어낼 수 있다고 한다.
베오3는 5월 21일부터 시작된 구글의 최고급 AI 요금제인 구글 AI 울트라 가입자에게 제공된다. 구글 AI 울트라는 출시 초기에는 미국 내에서만 제공된다.
Animate your story in your style with Veo 3.
— Google DeepMind (@GoogleDeepMind) May 20, 2025
Here are some of our favorite videos. Sound on.https://t.co/5wUMEaqNdD
pic.twitter.com/vl1R4nZJT4

또 베오3 개발 과정에서 크리에이터와 영화 제작자와의 협업을 통해 얻은 인사이트를 바탕으로 이전 모델인 베오2에도 새로운 기능이 추가됐다고 한다. 새롭게 추가된 기능에는 이미지 기반 생성 조정, 회전 및 줌 등 카메라 워크 설정, 프레임을 확장해 세로 영상을 가로 영상으로 변환하는 기능, 영상 내 오브젝트 추가 및 제거 등이 포함된다. 장면, 캐릭터, 오브젝트 이미지를 따로 제공하더라도 이를 통합해 영상 하나를 생성할 수 있다.
스타일을 정의하는 이미지를 제공하면 유사한 비주얼 동영상을 생성할 수 있다. 캐릭터 이미지를 제공하면 캐릭터 외형을 유지한 채 영상에 등장시키는 것도 가능하다. 관련 내용은 이곳에서 확인할 수 있다.
구글이 이미지 생성 AI인 이매진4(Imagen 4)를 5월 21일 발표했다. 이매진4는 최대 2K 해상도 이미지를 생성할 수 있으며 사실적인 사진 스타일부터 일러스트풍 이미지까지 고품질로 생성할 수 있다.
이매진4로 생성된 실사풍 이미지는 인물과 배경 모두 매우 사실적으로 재현된다. 접사 렌즈로 나비 날개를 촬영한 듯한 이미지도 가능하다. 세밀한 날개 무늬까지 표현할 수 있다. 일러스트 스타일 이미지도 생성 가능하다.
Get ready for Imagen 4
— Google DeepMind (@GoogleDeepMind) May 20, 2025capable of creating richer images, with more nuanced colors, intricate details and superior typography.
Tap each photo below to see more.pic.twitter.com/W0vDYu4Z4R
생성형 AI 성능을 평가하는 GenAI-Bench 결과를 보면 이매진4는 스테이블 디퓨전 3.5 라지나 FLUX.1 등과 비교해 높은 점수를 기록했다. 또 고품질 이미지를 짧은 시간 안에 생성할 수 있는 것으로 나타났다.
이매진4는 이미 제미나이 앱, 위스크(Whisk), 버텍스 AI에서 사용 가능하며 구글 워크스페이스 각종 서비스에서도 활용할 수 있다. 또 조만간 이매진3보다 최대 10배 빠른 고속 버전도 출시될 예정이다. 관련 내용은 이곳에서 확인할 수 있다.
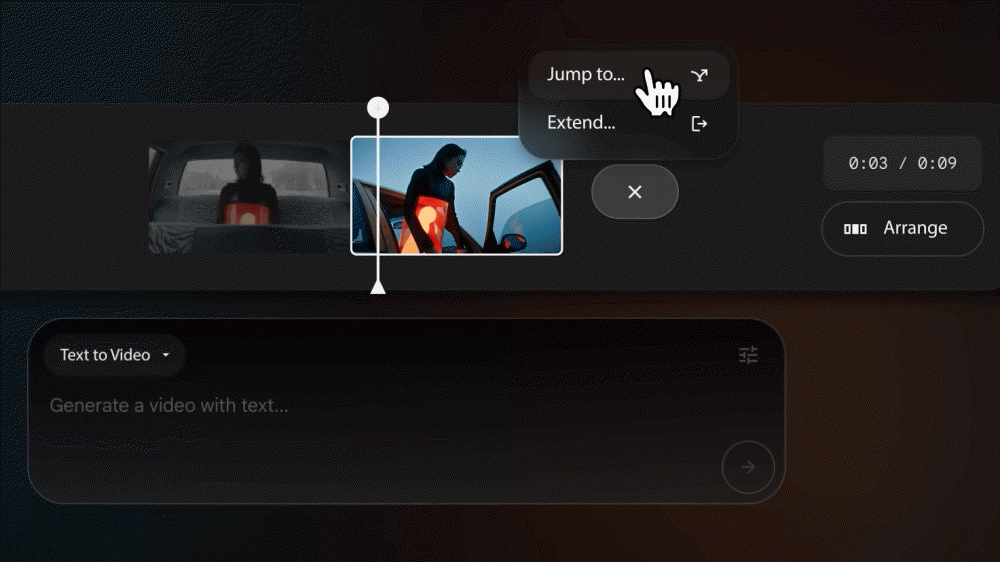
구글은 AI를 활용한 영화 제작 도구인 플로우(Flow)를 함께 발표했다. 플로우에는 동영상 생성 AI인 베오 3와 이미지 생성 AI 이매진 4가 통합되어 있으며 각 장면 생성부터 컷 편집까지의 일련의 흐름을 한 앱에서 실행할 수 있다.
플로우는 웹앱 형식 AI 도구다. 플로우는 지금까지 생성한 장면이 화면 내에 죽 늘어서 있고 화면 하단에는 새로운 장면을 생성하기 위한 입력 박스가 배치되어 있다. 장면 생성 방법은 텍스트를 기반으로 생성하는 텍스트투비디오(Text to Video), 이미지(프레임)를 기반으로 생성하는 프레임투비디오(Frames to Video), 다양한 소스를 기반으로 생성하는 인그레디언트투비디오(ingredients to Video) 3가지가 준비되어 있다.
프레임투비디오에서는 이미 존재하는 이미지를 소스로 사용할 수 있을 뿐만 아니라 이매진으로 새로운 소스 이미지를 생성할 수도 있다. 카메라 워크도 지정 가능하다. 인그레디언트투비디오에서는 풍경 소스나 피사체 소스 같은 여러 소스를 조합해 장면을 생성할 수 있다.
플로우 상에서 장면의 트리밍이나 재배열과 같은 컷 편집도 실행할 수 있다. 또 컷 편집 중 AI로 장면을 늘리거나 새로운 장면을 추가 생성하는 것도 가능하다. 이때 숲 속을 달리고 있는 장면 같은 대략적인 지시만 하면 제미나이가 적절한 프롬프트로 변환해 이미지대로의 장면을 생성해 준다. 영화가 완성되면 로컬에 다운로드할 수 있다. 플로우로 제작한 영상을 모은 웹사이트(Flow TV)도 공개됐다.
플로우를 사용하려면 구글 AI 프로 또는 새롭게 발표된 구글 AI 울트라에 가입해야 하며 플랜에 따라 사용할 수 있는 AI 모델이 달라진다. 플로우는 지금은 미국에서만 제공되고 있으며 가까운 시일 내에 대상 국가를 확대할 예정이다. 관련 내용은 이곳에서 확인할 수 있다.
◇ 제미나이 디퓨전‧코딩 에이전트‧UI 디자인도=구글은 이번 행사에서 초당 1,479개 토큰을 처리할 수 있는 확산 모델인 제미나이 디퓨전(Gemini Diffusion)을 발표했다. 지금까지 가장 빠른 모델보다 더 빠르게 콘텐츠를 생성한다고 한다.
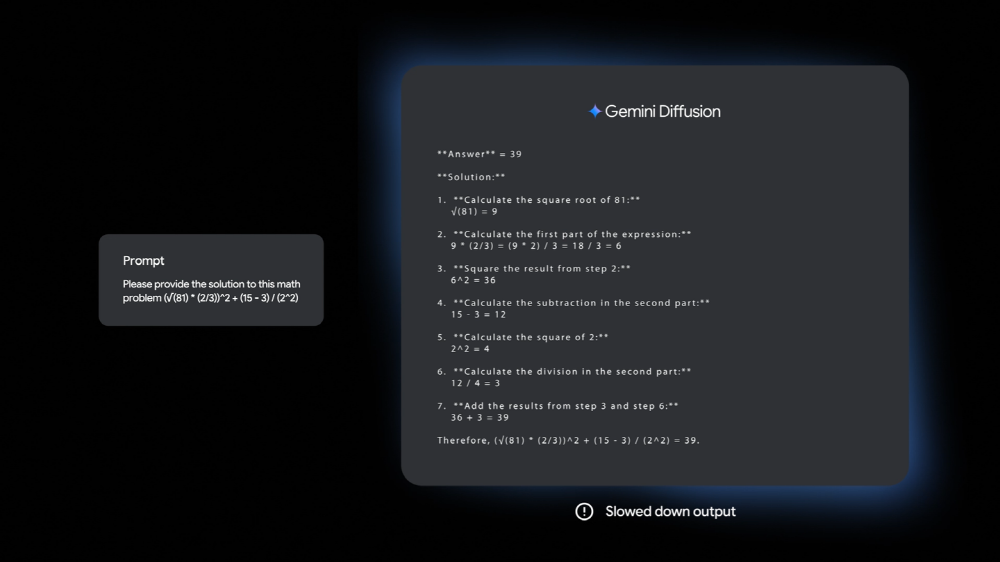
제미나이 디퓨전은 주로 이미지 생성 AI에 사용되는 확산 모델을 이용해 문장 생성을 수행한다. 구글에 따르면 기존 자기회귀형 언어 모델은 텍스트를 1단어(토큰)씩 생성하기 때문에 시간이 걸리고 출력 질과 일관성이 제한될 수 있다고 한다. 확산 모델은 이와 달리 텍스트를 직접 예측하는 대신 노이즈를 단계적으로 개선해 출력을 생성하도록 학습한다. 이를 통해 빠르게 출력을 처리할 수 있게 되고 출력 과정 중 오류를 수정할 수도 있게 된다. 구글에 따르면 프롬프트 입력부터 생성 시작까지의 오버헤드는 0.84초밖에 걸리지 않으며 오버헤드를 제외한 샘플링 속도는 초당 1,479개 토큰에 달한다고 한다.
구글은 제미나이 디퓨전은 수학 문제 해답이나 코드 생성과 같은 작업을 잘 수행하는 데 도움이 된다고 밝혔다. 벤치마크에서는 제미나이 디퓨전은 구글 저비용 모델인 제미나이 2.0 플래시-라이트(Flash-Lite_에 필적하는 성능을 보였다.
구글은 제미나이 디퓨전 데모를 공개했지만 접속하려면 대기 목록에 등록해야 한다. 또 더 빠른 제미나이 2.0 플래시-라이트를 곧 발표할 예정이라고 한다. 관련 내용은 이곳에서 확인할 수 있다.
구글은 AI를 탑재한 코딩 에이전트인 줄스(Jules) 공개 베타 버전도 출시했다. 줄스에는 강력한 코딩 능력을 가진 제미나이 2.5 프로가 탑재됐다.
줄스는 2024년 12월 발표된 AI 코딩 에이전트로 개발자가 자는 동안 소프트웨어 버그를 자동으로 수정하고 코드 변경을 준비할 수 있는 AI 코딩 어시스턴트로 설명된다.
줄스는 발표 후 6개월간 신뢰할 수 있는 테스터 선별 그룹에게만 제공됐지만 5월 마침내 공개 베타 버전으로 출시됐다. 줄스는 버그 수정이나 버전 번호 변경, 테스트 같은 작업을 자동으로 실행해주기 때문에 번거롭고 하기 싫은 작업을 줄스에게 맡겨 사용자가 자신이 하고 싶은 일에 집중할 수 있다고 강조한다.
Gemini 2.5 Pro is available in Jules, our asynchronous coding agent that can tackle complex tasks in large codebases that used to take hours. It can plan steps, modify files and more in just minutes.
— Google (@Google) May 20, 2025
Jules is now in public beta → https://t.co/RPCRFWtAv1 #GoogleIO pic.twitter.com/5zhRVFeUpm
줄스는 깃허브 워크플로 시스템과 통합되어 있어 리포지토리를 임포트하고 변경 사항을 브랜치하고 풀 리퀘스트 생성을 지원한다. 또 클라우드 가상 머신에서 코드를 클론해 변경 사항이 작동하는지 확인하는 기능과 기존 테스트를 실행하거나 새로운 테스트를 생성하는 테스트 스위트도 탑재됐다.
줄스는 또 코드를 작성하기 전 어떤 작업을 할지 플랜으로 보여주기 때문에 사용자가 플랜을 보고 줄스가 나아갈 방향을 확인하고 필요한 경우 플랜 수정을 요청할 수도 있다.
줄스는 비동기 AI 코딩 에이전트인 만큼 실제로 풀 리퀘스트가 제출되기 전 사용자 승인 절차가 있다. 또 변경 사항에 대해 음성으로 설명하는 오디오 요약(audio summary)도 생성해준다.
구글은 같은 날 간단한 프롬프트나 이미지를 기반으로 복잡한 UI를 디자인해주는 도구 스티치(Stitch)도 발표했다. 스티치에는 제미나이 2.5 프로 멀티모달 기능이 활용되어 있으며 이미지 입력이나 인터랙티브한 채팅, 테마 설정, 피그마에 붙여넣기 기능 등도 제공된다. 관련 내용은 이곳에서 확인할 수 있다.
구글은 그 밖에도 자사 AI로 생성된 콘텐츠를 빠르고 효율적으로 식별하기 위한 검증 포털 신스ID 디텍터(SynthID Detector)를 발표했다.
신스ID 디텍터는 구글이 이미 구현했으며 지금까지 100억 회 이용됐다는 전자 워터마크 신스ID를 검출하는 포털. 신스ID가 삽입된 이미지, 음성, 동영상, 텍스트를 포털에 올리면 콘텐츠가 스캔되어 신스ID가 탐지된다. 신스ID가 검출된 경우 포털은 신스ID가 삽입됐을 가능성이 높은 부분을 하이라이트로 표시한다. 음성의 경우 신스ID가 검출된 특정 부분을 정확히 짚어준다고 한다. 이를 통해 콘텐츠 진위를 확인할 수 있다.
SynthID – our groundbreaking digital watermarking technology – has already been used 10 billion times.
— Google DeepMind (@GoogleDeepMind) May 20, 2025
Today, we're introducing SynthID Detector, a new online portal designed to quickly identify if any part of digital content was generated by Google's AI tools.
Find out more… pic.twitter.com/mzIgL9ogbX

신스ID는 사람 눈으로는 식별할 수 없기 때문에 생성 과정에서 삽입하더라도 콘텐츠 품질에 영향을 주지 않는다고 한다. 또 신스ID는 이미지 픽셀에 삽입되어 메타데이터를 삭제하거나 이미지를 변형해도 그대로 유지된다.
신스ID는 처음에 AI로 생성된 이미지에만 초점을 맞췄지만 이후 제미나이, 이매진, 베오 모델 등으로 확장되어 음성, 동영상, 텍스트도 포함하게 됐다. 신스ID는 오픈소스화되어 있으며 엔비디아 AI 플랫폼인 엔비디아 코스모스(NVIDIA Cosmos)에서 생성된 동영상에 신스ID가 삽입되는 등 널리 사용되기 시작했다.
신스ID 디텍터는 초기 테스터를 대상으로 제공되고 있으며 저널리스트, 미디어 관계자, 연구자를 위한 대기자 명단이 마련되어 있다. 관련 내용은 이곳에서 확인할 수 있다.