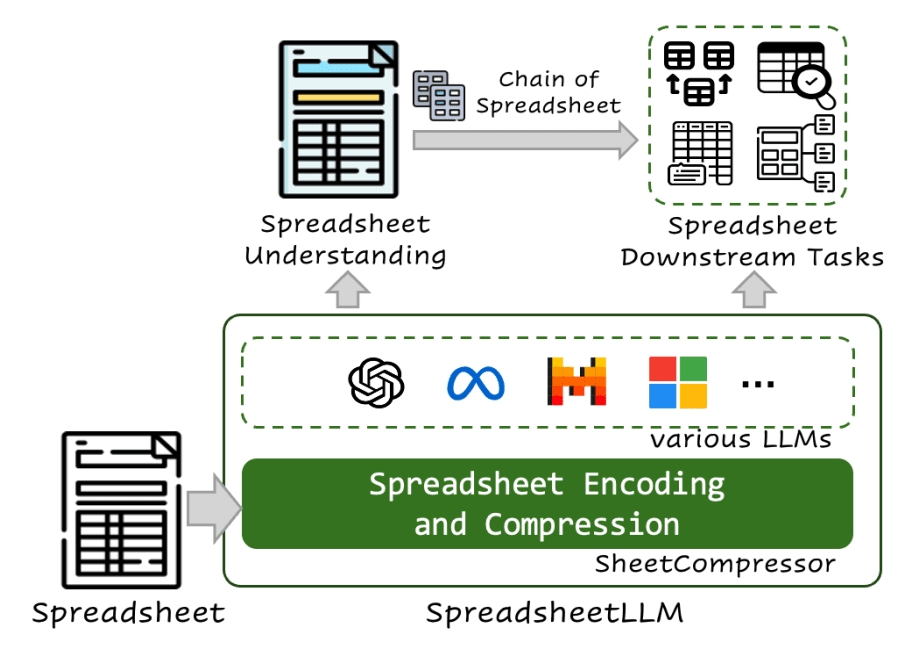
스프레드시트는 방대한 표와 다양한 서식 설정, 복잡한 계산식과 참조 등 요소를 갖고 있어 대규모 언어 모델(LLM)에게는 어려운 과제다. 마이크로소프트 연구진이 엑셀이나 구글 스프레드시트와 같은 기존 AI로는 이해하기 어려운 스프레드시트 처리를 염두에 둔 언어 모델 스프레드시트LLM(SpreadsheetLLM)을 발표했다.
7월 12일 프리프린트 서버 아카이브(arXiv)에 게재된 논문에서 마이크로소프트 연구팀은 스프레드시트를 언어 모델이 이해하기 쉬운 형식으로 변환하는 접근 방식을 채택한 스프레드시트LLM을 발표한 것.
이 접근 방식에서는 연구팀이 개발한 시트컴프레서(SheetCompressor)가 스프레드시트를 인코딩하고 압축해 언어 모델이 이해하거나 분석하기 쉬운 데이터로 변환한다. 이를 통해 GPT-4나 LLaMA 2와 같은 다양한 LLM이 스프레드시트를 더 깊이 이해할 수 있게 되어 예를 들어 GPT-4는 표 검출 테스트에서 78.9% 점수를 얻어 기존 접근 방식보다 12.3% 높은 성적을 거뒀다.
시트컴프레서는 표 구조를 정의하는 중요한 행과 열을 식별하는 효율적인 레이아웃 이해를 위한 구조적 앵커, 비어 있지 않은 셀 텍스트에 인덱스를 부여해 데이터 일관성을 유지하면서 토큰 사용을 최적화하는 토큰 효율화를 위한 전치 인덱스 번역, 유사 형식이나 수치 셀을 그룹화해 사용하는 토큰을 줄이는 수치 셀 데이터 포맷 집계 3가지 구성 요소로 이뤄져 있다.
연구팀에 따르면 시트컴프레서를 사용하면 데이터가 최대 96% 압축되어 LLM이 토큰 제한 내에서 대규모 데이터세트를 처리할 수 있게 된다고 한다.
스프레드시트LLM의 강점은 스프레드시트 데이터에 대한 접근성을 개선하고 더 이해하기 쉽게 만들 수 있다는 것. LLM 힘으로 사용자는 복잡한 수식이나 프로그래밍 언어 대신 자연어 처리로 스프레드시트를 참조하거나 작성할 수 있어 예를 들어 조직 내 더 많은 개인이 데이터 기반 의사 결정을 쉽게 할 수 있는 등 이점이 기대된다.
또 스프레드시트LLM은 데이터 정리나 포맷, 집계 등 스프레드시트 데이터 분석에 필요한 많은 번거로운 작업을 자동화할 수 있어 기업 직원은 더 가치 있는 일에 리소스를 늘릴 수 있다.
마이크로소프트는 이미 마이크로소프트 365 코파일럿과 같은 제품으로 오피스 스위트와 AI 통합을 진행하고 있으며 스프레드시트LLM 등장으로 스프레드시트에서도 AI를 활용할 수 있게 될 가능성이 생겼다.
스프레드시트LLM이 정식 출시될지 여부와 시기는 불분명하지만 보도에선 스프레드시트LLM이 연구에서 실제 사용 가능한 애플리케이션으로 전환될 때 스프레드시트 작업이 어떻게 변화하고 기업 데이터 주도 의사 결정에 어떤 가능성을 가져올지 보는 것이 기대된다며 마이크로소프트가 이 AI 주도 혁신 최전선에 서면서 그 중에서도 엑셀과 스프레드시트를 중심으로 한 업무의 미래는 이전보다 더 밝아질 것 같다고 언급했다. 관련 내용은 이곳에서 확인할 수 있다.