애플 연구자가 스마트폰 앱 UI를 이해하기 위해 설계한 멀티모달 대규모 언어 모델(MLLM)인 페렛-UI(Ferret-UI)를 개발했다는 논문을 아카이브에 공개했다.
챗GPT 같은 채팅봇 AI 시스템 기반이 되는 대규모 언어 모델(LLM)은 주로 웹사이트에서 수집된 방대한 텍스트로부터 학습된다. 구글 제미나이 같은 MLLM은 텍스트 뿐 아니라 이미지, 동영상, 오디오 등 비텍스트 정보도 학습하는 게 핵심이다.
하지만 MLLM은 스마트폰 앱 성능이 뛰어나지 않다고 알려져 있다. 이유 중 하나는 학습에 사용되는 이미지와 동영상 대부분이 스마트폰 화면 종횡비와 다른 가로 형태이기 때문. 또 스마트폰에선 아이콘과 버튼 등 인식해야 할 UI 요소가 자연 이미지 객체보다 작다는 문제도 있다.
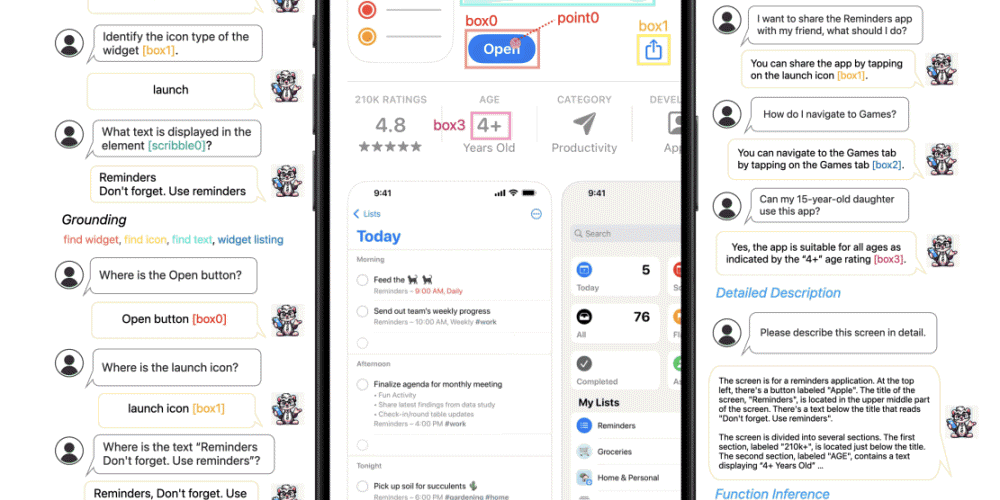
이번에 애플 연구자가 발표한 페렛-UI는 스마트폰 모바일 앱 화면을 인식할 수 있도록 설계된 생성 AI 시스템. 스마트폰 UI 화면은 보통 세로 긴 종횡비를 가지며 아이콘, 텍스트 등 작은 대상을 포함하고 있다. 이에 대응하기 위해 페렛-UI에선 이미지 세부 사항을 확대하고 강화된 시각적 특징을 활용하는 애니 레졸루션(any resolution) 기술이 도입됐다. 이를 통해 페렛-UI는 화면 해상도에 관계없이 UI 세부사항을 정확히 인식할 수 있게 됐다.
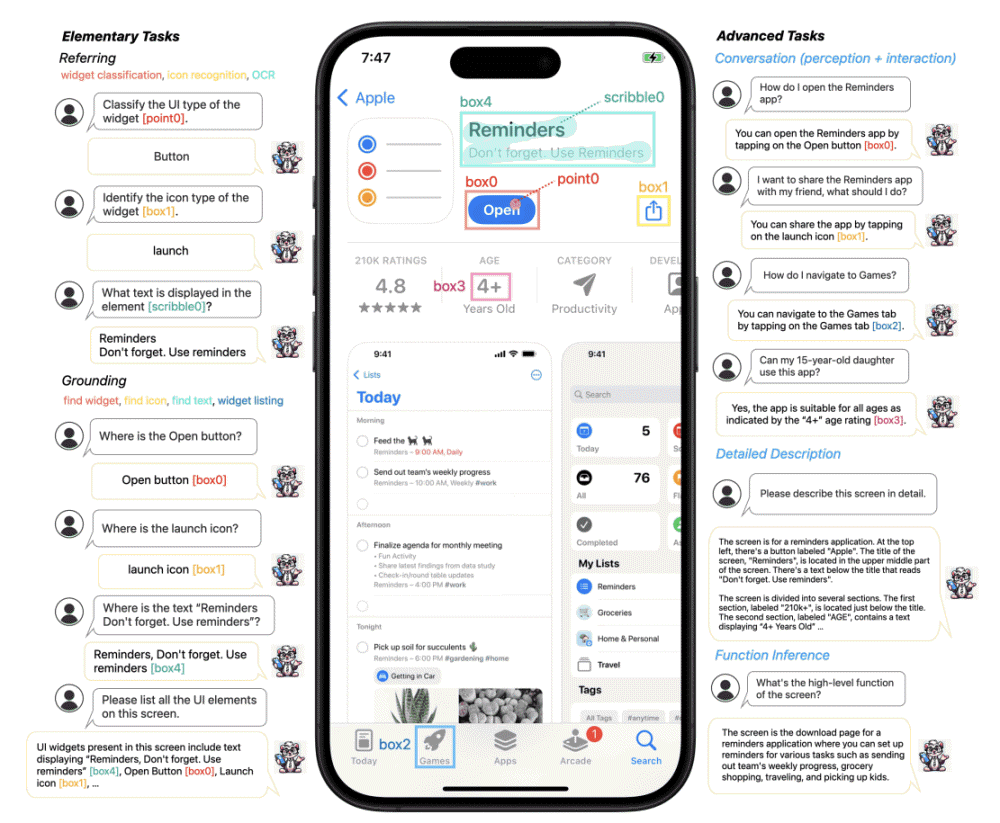
또 페렛-UI는 아이콘 인식, 텍스트 검색, 위젯 목록화 같은 기본 UI 작업에 대한 광범위한 학습 샘플을 세심하게 수집했다. 이런 샘플에는 영역별 주석이 달려 있어 언어와 이미지 연결과 정확한 참조가 용이하다. 다시 말해 페렛-UI는 다양한 UI 샘플을 대량으로 학습해 다양한 UI를 정확히 이해할 수 있게 됐다.
논문에 따르면 페렛-UI는 GPT-4V, 기타 기존 UI 관련 MLLM보다 더 나은 성능을 보이고 있다고 한다. 이는 페렛-UI 애니 레졸루션 기술, 대규모 다양한 교육 데이터, 고도의 작업에 대한 대응 등이 UI 이해와 조작에 있어 높은 효과를 발휘하고 있음을 시사한다.
또 페렛-UI 모델 추론 능력을 높이기 위해 상세한 설명, 지각/상호작용 대화, 기능 추론 등 고도의 작업을 위한 데이터세트가 추가로 컴파일되고 있다. 이를 통해 페렛-UI는 단순한 UI 인식을 넘어 더 복잡하고 추상적인 UI 이해와 상호작용이 가능해질 것이다.
페렛-UI가 실용화되면 접근성 향상을 기대할 수 있다. 시각 장애 등으로 스마트폰 화면을 볼 수 없는 사람도 화면에 표시된 내용을 요약해서 AI가 사용자에게 전달할 수 있게 된다. 또 스마트폰 앱을 개발할 때 페렛-UI로 화면을 인식시켜 앱 UI의 명확성과 사용성을 더 빨리 확인할 수 있게 된다.
나아가 스마트폰에 최적화된 멀티모달 AI라는 점에서 아이폰에 탑재된 AI 어시스턴트 시리와 결합하면 앱을 사용한 고도의 작업을 시리로 자동화할 수 있을 것으로 기대된다. 관련 내용은 이곳에서 확인할 수 있다.