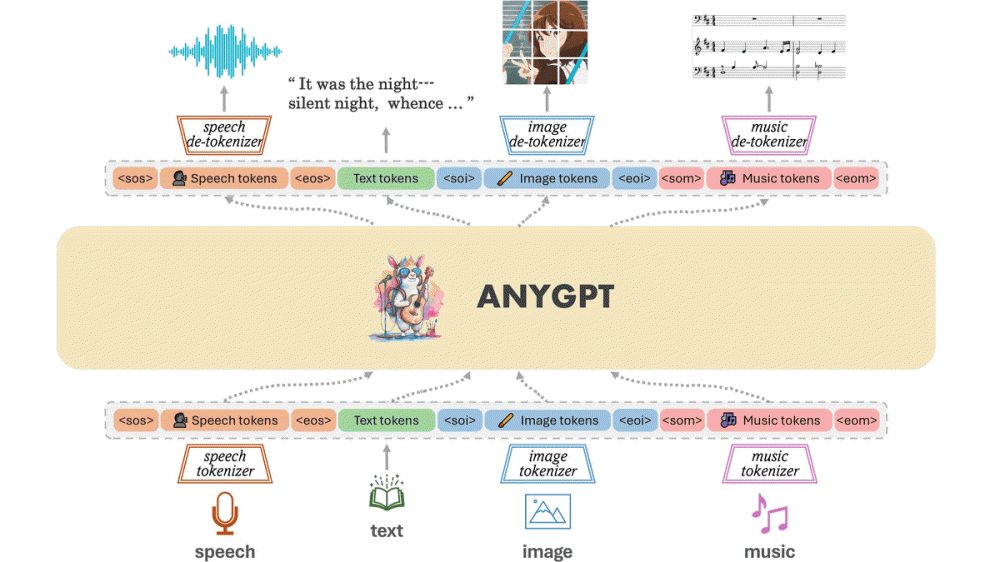
애니GPT(AnyGPT)는 음성과 텍스트, 이미지, 음악 등 여러 종류 데이터를 한 번에 처리할 수 있는 멀티모달 대규모언어모델이다.
기존 대규모언어모델 아키텍처나 학습 패러다임을 바꾸지 않고 안정적으로 학습할 수 있는 새로운 멀티모달 LLM인 것. 애니GPT는 데이터 레벨 전처리에만 의존하고 있어 새로운 언어를 짜넣는 것처럼 새로운 모더리티 LLM에의 원활한 통합을 촉진하는 게 가능하다. 멀티모달 얼라인먼트 사전 학습에 의해 멀티모달 텍스트 중심 데이터세트를 구축해 생성 모델을 이용해 대규모 애니투애니(Any-to-Any) 그러니까 어떤 데이터 형식에서 임의 데이터 형식으로 출력 가능한 멀티모달 명령어 데이터세트를 구축한다.
애니GPT 멀티모달 명렁어 데이터세트는 다양한 모달리티를 복잡하게 결합한 멀티턴 대화 10만 8,000개 샘플로 이뤄져 모델이 멀티모달 입출력 모든 조합을 처리할 수 있다. 또 개발팀은 애니GPT가 모든 모달리티에 걸쳐 특수화된 모델에 필적하는 성능을 달성하면서 애니투애니 멀티모달 대화를 촉진할 수 있다는 걸 나타내고 있으며 이산 표현이 LLM 내 복수 모달리티를 효과적이고 편리하게 통합할 수 있다는 걸 입증하는데 성공했다.
애니GPT는 음성과 텍스트, 이미지, 음악이라는 여러 종류 데이터를 개별적으로 토큰화하고 있으며 이에 따라 LLM은 멀티모달 이해와 생성을 자체 회귀적으로 수행한다. 데이터 전처리와 후처리만 필요하며 모델 아키텍처와 학습 목표를 바꿀 필요가 없다.
애니GPT 멀티모달 명렁어 데이터세트는 애니인스트럭트(AnyInstruct)라고 불리며 이 빌드 프로세스는 멀티모달 요소를 포함한 텍스트 기반 상호작용 생성, 텍스트에서 멀티모달로 변환이라는 2가지 단계로 나뉘어져 있다. 첫 단계인 멀티모달 요소를 포함한 텍스트 기반 대화 생성에선 주제 시나리오 텍스트 형식 대화를 생성하고 2번째 단계인 텍스트에서 멀티몰타로 변환에선 최종 멀티모달 대화가 생성된다.
애니GPT는 멀티모달 LLM으로 음성과 텍스트, 이미지, 음악에서 다양한 형식 데이터를 출력할 수 있다. 프롬프트에서 여러 데이터 형식을 입력할 수도 있다. 예를 들어 이 이미지에서 음악을 생성해달라거나 이 음악을 이미지로 변환해달라는 프롬프트도 사용할 수 있다. 관련 내용은 이곳에서 확인할 수 있다.