엔비디아가 음성 기술 콘퍼런스인 인터스피치(INTERSPEECH) 2021 기간 중 인간 같은 표현으로 목소리를 낼 수 있는 AI를 개발 중이라고 발표했다.
합성 음성 자동 안내 서비스나 예전 내비게이션 안내는 기계적이었다. 이에 비해 스마트폰이나 스마트 스피커에 탑재한 음성 비서는 상당히 정교하게 진화했다. 하지만 여전히 실제 인간에 의한 대화 음성과 합성 음성 사이에는 큰 차이가 있다. 실제 인간 목소리인지 AI 합성 음성인지 구별하기 쉽다. 엔비디아에 따르면 AI가 인간 목소리에 포함된 복잡한 리듬과 억양을 완벽하게 모방하기는 어렵다.
엔비디아가 새로운 제품과 기술을 소개하는 영상에선 지금까지 인간이 내레이션을 맡았다. 지금까지 음성 합성 모델로 합성할 수 있는 음성 템포와 음정 제어에 한계가 있었기 때문에 인간 내레이터처럼 시청자 감정을 자극하는 것 같은 말투는 불가능했기 때문이다.
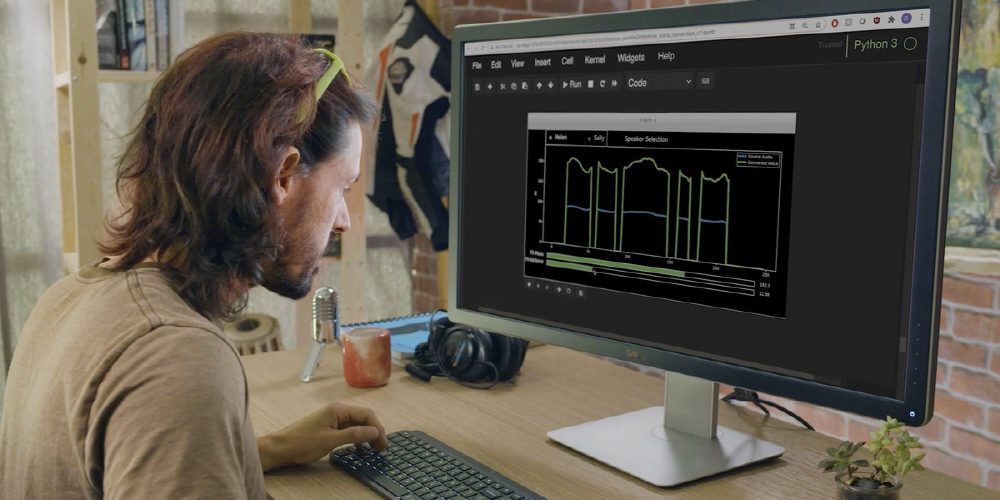
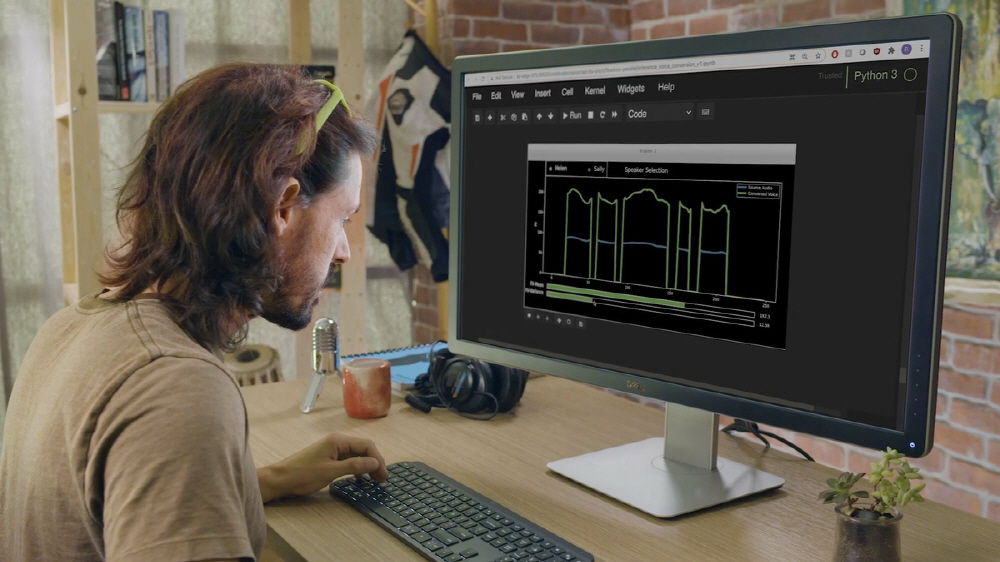
하지만 엔비디아 음성 합성 연구팀은 텍스트 음성 합성 기술 RAD-TTS를 개발하고 엔비디아 음성 합성 기술을 크게 끌어올렸다. 엔비디아가 자동 음성 인식과 자연어 처리 텍스트 음성 합성 연구를 위한 오픈소스로 개발하는 대화형 AI 툴킷이 바로 엔비디아 네모(NVIDIA NeMo)다. 인간 목소리를 악기로 보고 합성된 목소리 피치와 지속 시간, 강도를 프레임 단위로 정확하게 제어할 수 있다.
보통 기계 음성은 독특한 억양이 있어 위화감이 있다. 하지만 엔비디아 네모로 변환한 음성은 전혀 위화감 없이 부드럽게 재생된다. 또 AI 측에서 합성된 음성을 조정해 특정 단어를 강조하거나 내레이션 속도를 바꿔 영상에 맞출 수 있다.
음성 합성 내레이션 외에도 음악 제작 장면에서도 활약할 수 있다. 예를 들어 음악을 만들 때 코러스 파트에 여러 명 목소리를 녹음해 겹쳐야 한다. 하지만 합성 음성을 이용해 다수를 모으지 않아도 코러스 파트를 수록할 수도 있다.
엔비디아 네모에 수록되어 있는 AI 모델은 엔비디아 DGX 시스템에서 수만 시간 음성 데이터를 이용해 학습해 엔비디아 GPU인 텐서 코어를 이용해 작동한다. 또 엔비디아 네모는 76개 언어, 1만 4,000시간 음성 데이터를 포함하는 데이터세트인 모질라 커먼 보이스(Mozilla Common Voice)에서 학습한 모델도 볼 수 있다고 한다. 엔비디아는 세계 최대 오픈소스 음성 데이터세트를 이용해 음성 기술 민주화를 목표로 하고 있다고 밝히고 있다. 엔비디아 네모는 깃허브에 소스가 공개되어 있다. 관련 내용은 이곳에서 확인할 수 있다.