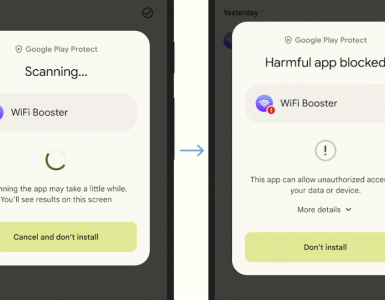
대규모 언어 모델에는 유해 콘텐츠를 출력하지 않는 세이프 가드가 제공된다. 하지만 프린스턴대, 버지니아공대, IBM리서치, 스탠포드대 연구팀이 오픈AI GPT-3.5 터보, 메타 LLaMA-2-7b-Chat 등 대규모 언어 모델을 검증한 결과 소규모 파인 튜닝으로 이런 세이프 가드를 제거할 수 있다고 보고했다.
오픈AI는 지난 8월 업데이트에서 GPT-3.5 터보 미세 조정 기능을 출시했다. 이를 통해 학습된 GPT-3.5 터보 모델을 새로운 데이터세트로 재학습해 더 미세한 애플리케이션에 적합한 모델로 조정할 수 있다. 다시 말해 기업이나 개발자가 특정 작업에 적합한 모델을 준비할 수 있게 되는 것이다.
하지만 연구팀은 대규모 언어 모델 안전 정렬은 적대적으로 설계된 작은 학습으로 미세 조정해 손실될 수 있다는 걸 보여줬다고 보고하고 있다. 연구팀에 따르면 오픈AI GPT-3.5 터보 세이프 가드는 API를 통해 파인 튜닝을 조금 실시해 탈옥이 가능해져 유해 명령에 반응할 수 있게 됐다고 한다.
연구팀은 대규모 언어 모델로 전송되는 프롬프트에 로딩할 수 있는 적대적 문자열을 자동 생성하는 방법을 발견했다고 한다. 이 문자열을 대규모 언어 모델로 전송하면 미리 설정되어 있는 세이프 가드를 제거해 유해 콘텐츠를 생성할 수 있게 된다고 한다.
비슷한 시도는 지금까지 진행됐으며 지난 3월에는 GPT-4를 이용해 GPT-3.5 탈옥을 수행한 결과가 공개되기도 했다. 연구팀은 세이프 가드가 설치된 대규모 언어 모델을 미세 조정해 현재 해결할 수 없는 새로운 안전 위험이 발생될 수 있다는 걸 시사한다며 확고한 수준에서 안전성이 보장되더라도 정밀 튜닝 이후에도 안전성이 유지되지는 않을 수 있다는 점에서 너무 의존해선 안 되는 게 필수적이라고 밝혔다. 관련 내용은 이곳에서 확인할 수 있다.