

드롭박스(Dropbox)는 자사 서비스에서 파일 미리보기 기능을 기계학습으로 효율화해 170만 달러 비용 절감을 달성했다.
드롭박스에 올린 파일을 빠르게 미리 볼 수 있는 리베라(Riviera)라는 내부 시스템을 이용해 사전에 파일 미리보기 데이터를 생성한다. 하지만 사전에 생성된 데이터가 이용되지 않고 낭비되는 경우도 있었기 때문에 기계학습으로 미리 생성해야 할 데이터를 예측, 데이터를 생성할 때 시스템 자원을 절약하는 시스템인 카네스(Cannes)가 발족하게 됐다.
카네스를 개발하면서 개발팀이 중시한 건 예측이 벗어난 경우 성능 저하 허용 범위와 기계학습 모델의 단순함이다. 미리보기를 위한 허용 범위에 선을 그어 선긋기를 기계학습으로 정밀하게 하는 걸 목표로 했다. 이에 대해선 가능하면 기계학습 모델을 단순화해 왜 예측 결과가 태어난지 명확히 하고 도입 초기 디버깅을 용이하게 할 목적을 세웠다고 한다.
기계학습 모델 구축에는 파일 확장자나 저장된 파일 종류에 따른 계정 구분 그리고 최근 30일간 계정 활동을 입력 데이터로 채택했다. 이 방법에 의해 구축한 카네스 v1(Cannes v1) 정도 목표를 달성하고 10억원대 비용 절감을 추산했다고 한다. 프로덕션 환경 트래픽을 이용한 A/B 테스트 등을 거쳐 미리 응답속도 저하가 허용 범위 내에 있는지를 실제로 확인해 개발팀은 카네스를 시스템에 도입하게 됐다.
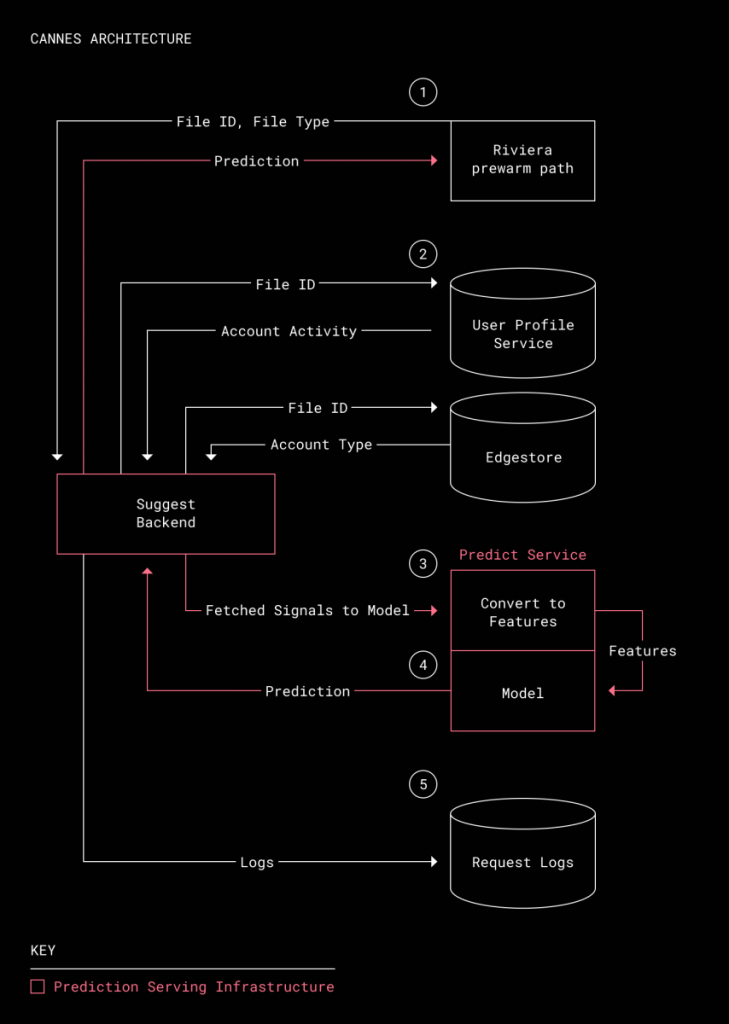
미리 보기 데이터 생성을 담당한 리베라는 먼저 미리보기 데이터를 생성할 때 파일 ID나 유형을 카네스로 보낸다. 카네스는 파일 ID를 바탕으로 외부 데이터베이스에서 계정 유형과 사용량을 수집한다. 수집한 데이터는 특징을 나타내는 벡터로 변환된 뒤 기계학습 모델에 투입되는 모델은 앞으로 60일간 파일 미리보기가 행해지는지를 예측, 예측 결과는 리베라에 전송하는 동시에 디버깅 특징과 함께 로그로 저장되는 구조다.
현재 카네스는 드롭박스에서 거의 모든 트래픽에 적용되고 있으며 개발팀은 미리보기 데이터 사전 생성에 소요되는 연간 비용을 추산대로 상당 금액을 줄일 수 있다. 카네스 운용비용은 연간 9,000달러이기 때문에 상당한 큰 비용 절감을 달성할 수 있다. 개발팀은 앞으로 더 복잡한 모델을 실험하고 예측 정확도 향상을 목표로 하는 것 외에 특징에 대한 재학습을 시켜 모델을 조정할 미세 조정을 실시할 예정이라고 한다. 관련 내용은 이곳에서 확인할 수 있다.























