

구글이 검색엔진에 새로운 언어 처리 기술인 BERT를 도입해 검색 결과를 개선한다. 구글 측은 BERT 도입에 대해 지난 5년간 가장 큰 비약적 발전을 실현하는 한편 검색 역사에서도 가장 큰 도약을 이룰 개선이 될 것이라고 밝히고 있다. BERT 도입은 먼저 영문 구글 검색에서 도입하지만 다른 언어로도 확대할 예정이다.
BERT(Bidirectional Encoder Representations from Transformers)는 기계학습을 기반으로 한 새로운 언어 처리 모델이다. 지금까지의 검색엔진에서 골칫거리였던 문맥에 따른 단어의 해석을 보다 정밀하게 실시할 수 있다. 구글은 BERT 학습 모델을 2018년 오픈소스로 발표한 바 있다.
문맥에 따른 단어 해석은 여러 의미를 지닌 단어가 있을 때 그 말을 포함한 전체 문장을 보고 적절한 의미로 선택한다는 것이다. 여러 의미로 쓰인 단어라면 당연히 단어만 보면 어떤 의미로 사용한 것인지 알 수 없다. 이런 모호한 단어를 포함한 문구에 대해 BERT는 문장 전체를 참조해 의미를 선택한다.
BERT를 검색에 도입하면 구어를 그대로 검색엔진에 넣어도 정확도가 늘어난다. 구글은 영어 검색엔진에서 몇 가지 예를 소개하고 있다. 예를 들어 ‘Can you get medicine for someone pharmacy’라는 문장은 자신이 아니라 병에 걸린 가족과 친구를 위해 약을 사는 방법을 찾는 장면을 상상할 수 있지만 지금까지의 검색엔진 알고리즘은 ‘someone’이 핵심 문구라는 걸 인식하지 못하고 약국에서 약을 사는 방법이라고 해석 결과를 표시했다.
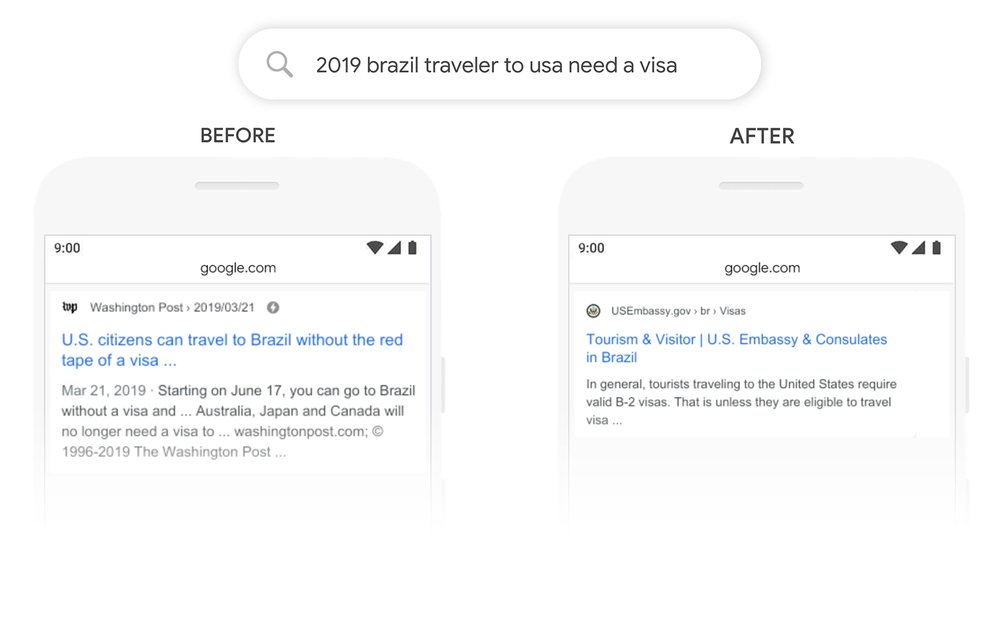
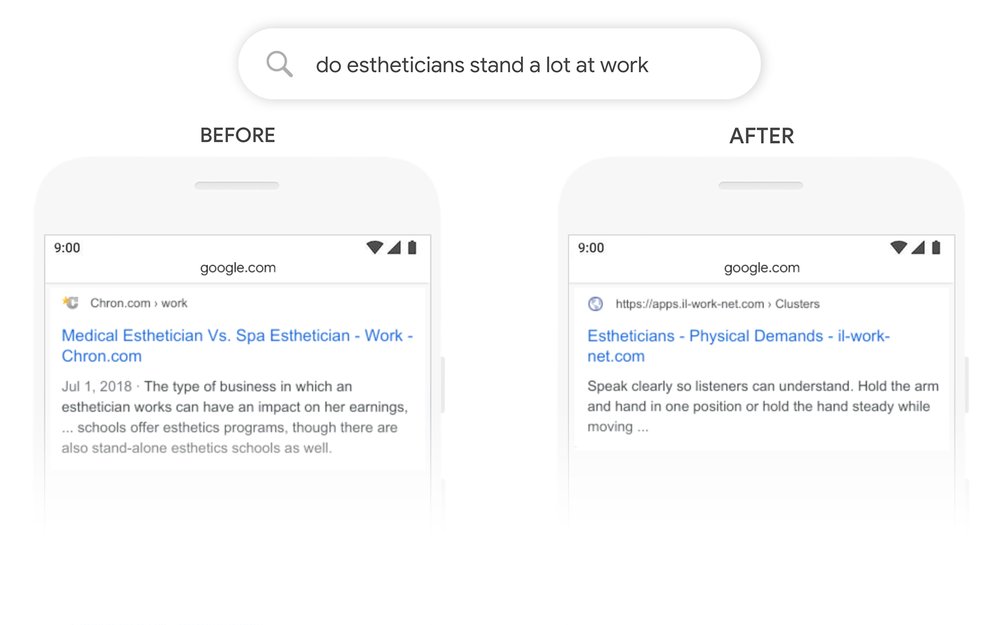
또 ‘do estheticians stand a lot at work’라는 문장에선 ‘stand’는 여러 의미가 있고 ‘at work’는 원래 속어다. 지금까지 구글 검색에선 인식하기 어려운 문장이었던 것. 이런 문구도 BERT는 문맥상 필요 없는 의미를 빼고 관련성 높은 결과를 표시할 수 있다고 한다.
한편 BERT 모델을 적용해도 잘 안되는 것도 존재한다. 예를 들어 ‘what state is south of Nebraska’라는 문장의 원래 뜻은 네브라스카 남쪽에 있는 주를 묻는 것이지만 BERT는 캔자스가 아닌 남쪽 네브래스카 작은 커뮤니티 홈페이지를 표시한다.
BERT 모델은 지금은 영어 버전 구글 검색에만 사용되고 있지만 다국어 배포에도 흥미로운 특징이 있다. 구글은 BERT가 하나의 언어로 학습한 모델을 다른 언어로도 전개할 수 있다고 설명하고 있다. 영어 학습 모델 일부를 시험적으로 응용한 결과 우리나라와 힌디어, 포르투갈어 등 20개 언어 검색 결과를 크게 개선할 수 있었다고 한다.
구글 검색은 15년이라는 긴 역사 속에서 전 세계 수많은 지역 검색 시장을 석권했다. 지금도 매일 수십억 건 검색을 기록한다. 이런 검색 알고리즘 변경은 웹사이트 운영자나 사용자에게 큰 영향을 미칠 수 있다. 한편 구글은 구글 검색 알고리즘 블랙박스로 구조를 공개적으로 설명하는 일은 거의 없다. 물론 BERT는 구글 검색 중 한 가지 요소에 불과하다. 하지만 구글이 검색 업데이트 발표회를 열고 구조를 설명하는 행위 자체는 지금까지 구글에선 볼 수 없었던 움직임이기도 하다. 구글 입장에선 구글 검색 투명성을 향상시킬 필요성을 느끼고 있을지도 모른다. 관련 내용은 이곳에서 확인할 수 있다.























