
수많은 학습 자원을 사용하는 메타 LLaMA 2-7B」를 넘어선 성능을 갖추면서도 학습 비용을 1억 원 이하로 억제할 수 있는 대규모 언어 모델인 JetMoE-8B가 등장했다.
JetMoE-8B는 AI 개발 기업 마이쉘(MyShell)이 공개한 것으로 기존 모델보다 훨씬 낮은 학습 비용으로 인해 민간용 GPU로도 모델 미세 조정이 가능하다고 한다. 또 공개 데이터세트 만을 사용해 학습했으며 코드는 오픈소스로 공개되어 독점적 리소스가 필요 없다는 특징이 있다.
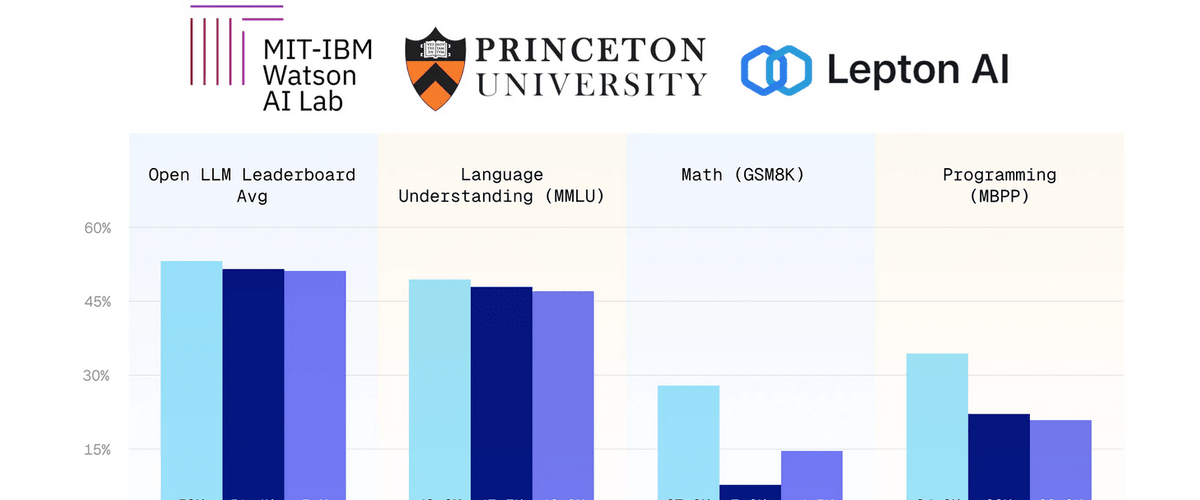
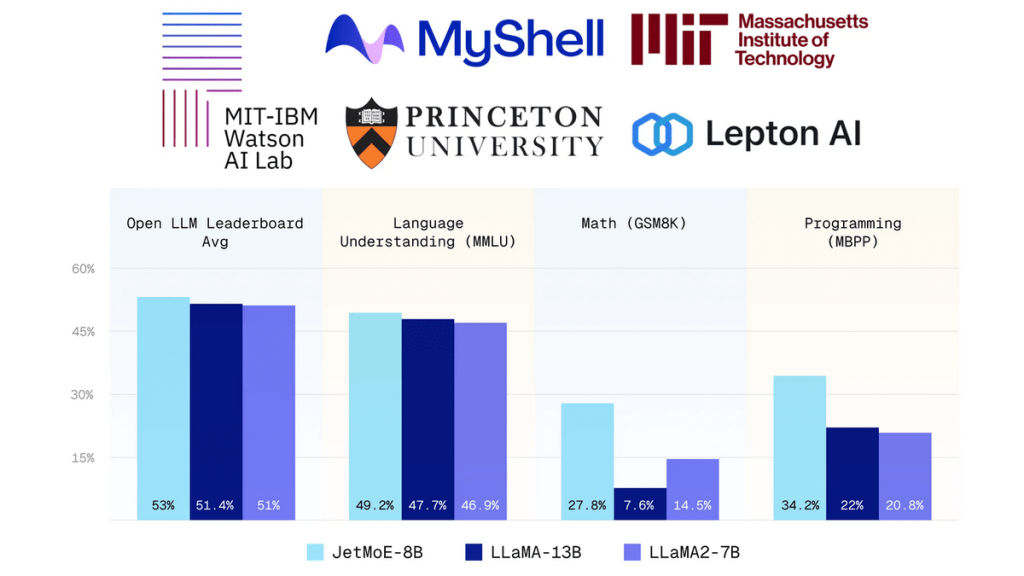
JetMoE-8B를 LLaMA 2-7B, DeepseekMoE-16B, Gemma-2B 등과 비교해보면 JetMoE-8B는 추론에서 활성 파라미터는 2.2B로, 이는 계산 비용이 LLaMA 등에 비해 낮다는 걸 의미한다. MBPP, MMLU 같은 데이터세트를 활용한 벤치마크에서 JetMoE-8B는 LLaMA 2-7B와 다른 모델을 능가하는 점수를 기록했다. 관련 내용은 이곳에서 확인할 수 있다.






















