대규모언어모델 대부분은 주로 영어와 중국어 데이터로 학습된다. 이 탓에 다른 언어 수천 종류에 대해선 문장 생성 정밀도가 떨어지는 문제가 있다. 스타트업 코히어(Cohere) 산하 비영리 연구 조직(Cohere for AI)이 발표한 LLM인 아야(Aya)는 119개국 연구자 3,000명이 참여한 프로젝트로 개발되어 기존 오픈소스 LLM 2배 이상 언어를 커버하고 있다.
코히어포AI는 LLM과 AI가 세계적인 기술 상황을 변화시키는 가운데 전 세계 많은 커뮤니티는 기존 모델 언어 제한에 의해 지원되지 않은 채로 남아 있다며 격차를 더 확대할 수 있다고 밝히고 있다.
코히어포AI가 제공하는 데이터세트는 100개 이상 언어로 기계 번역된 데이터를 포함한다. 이 언어 절반은 아제르바이잔어, 웨일스어 등 기존 텍스트 데이터세트에서 충분히 학습할 수 없다고 여겨지는 언어다. 더구나 67개 언어에 대해선 흐릿한 화자가 주석을 붙인 20만 4,000종류 프롬프트와 결과에 의해 문화적 뉘앙스와 문맥을 파악하려는 데이터세트로 작성됐다고 한다.
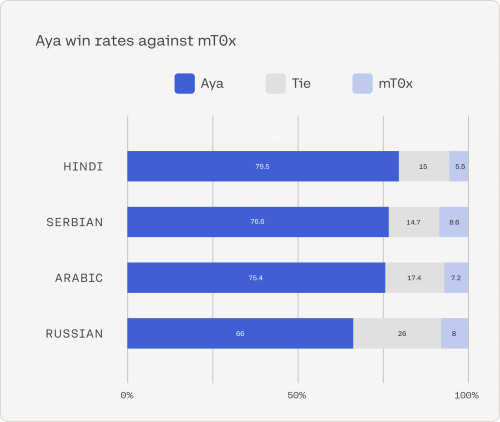
코히어포AI에 따르면 벤치마크 테스트에서 아야 성능은 mt0과 bloomz를 크게 웃돌고 다른 주요 오픈소스 모델에 대한 인간 평가에서 항상 75%, 시뮬레이션에서의 승률에선 80∼90% 점수를 냈다고 한다. 아야는 소말리아어와 우즈벡어 등 지금까지 다른 LLM에서 지원되지 않던 50개 이상 언어를 다루고 있다는 설명이다.
코히어 측은 발족 당시 얼마나 거대한 프로젝트가 될지 전혀 알지 못했지만 마지막으로 5억 1,300만 개가 넘는 프로젝트에서 미세 조정된 주석이 데이터세트에 추가됐다고 밝히고 있다. 아야 모델은 아파치 라이선스 2.0 하에서 허깅페이스 저장소에서 호스팅된다. 또 114개 언어와 5억 1,300만 종류 프롬프트가 포함된 데이터세트에 대해서도 아파치 라이선스 2.0 하에서 허깅페이스에서 공개되고 있다. 관련 내용은 이곳에서 확인할 수 있다.