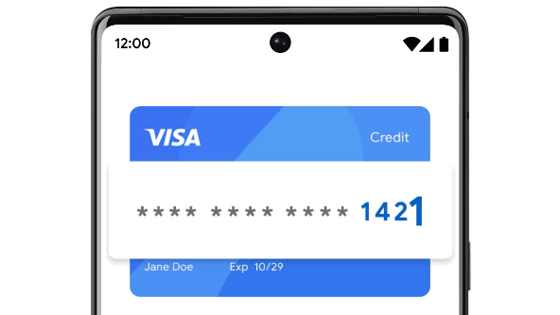
구글이 인터넷 매장 등에서 결제할 때 자신이 소지한 신용카드 번호와는 다른 번호를 생성하는 서비스인 버추얼카드(Virtual Cards)를 발표했다. 버추얼카드를 이용하면 사용자는 신용카드 번호 유출에 대해 걱정하지 않고 인터넷 쇼핑을 즐길 수 있다.
인터넷에서 쇼핑할 때 신용카드를 이용하면 간편한 결제가 가능하지만 신용카드 번호가 인터넷몰에 유출되어 버릴 위험에 불안을 느낄 수 있다. 구글페이나 애플페이 같은 결제 수단을 이용하면 신용카드 번호를 숨기면서 대금을 지불할 수 있지만 이런 결제 수단은 인터넷몰에 따라선 사용 불가능한 일도 있다.

이번에 구글이 발표한 버추얼카드는 안드로이드나 PC에 설치한 크롬이 신용카드 정보 입력란을 검지하면 가상 신용카드 번호를 생성해주는 서비스. 인터넷몰이 신용카드 결제에 대응하면 이용할 수 있다.
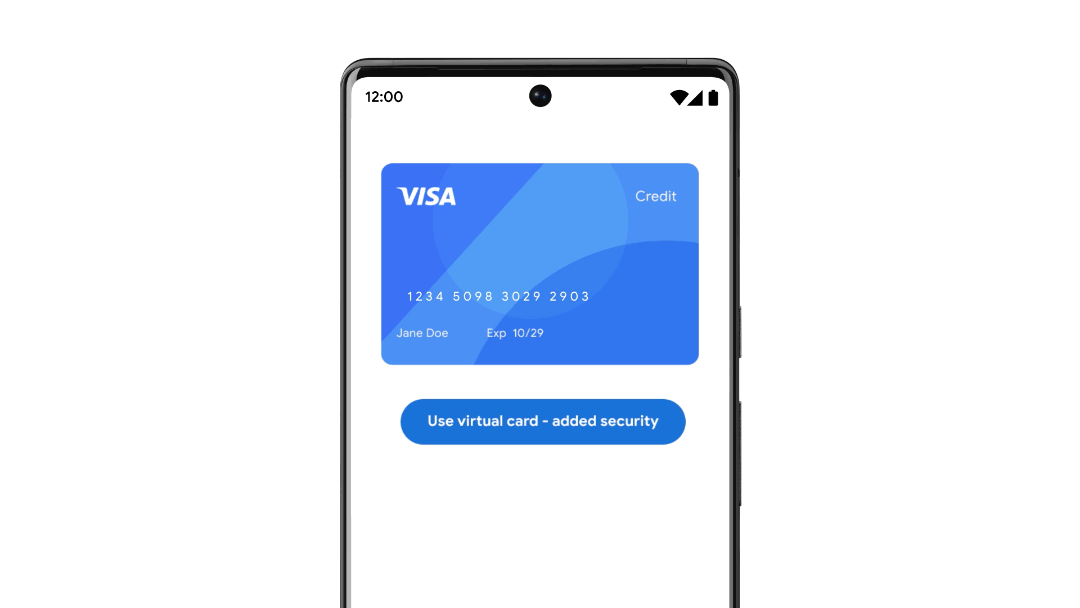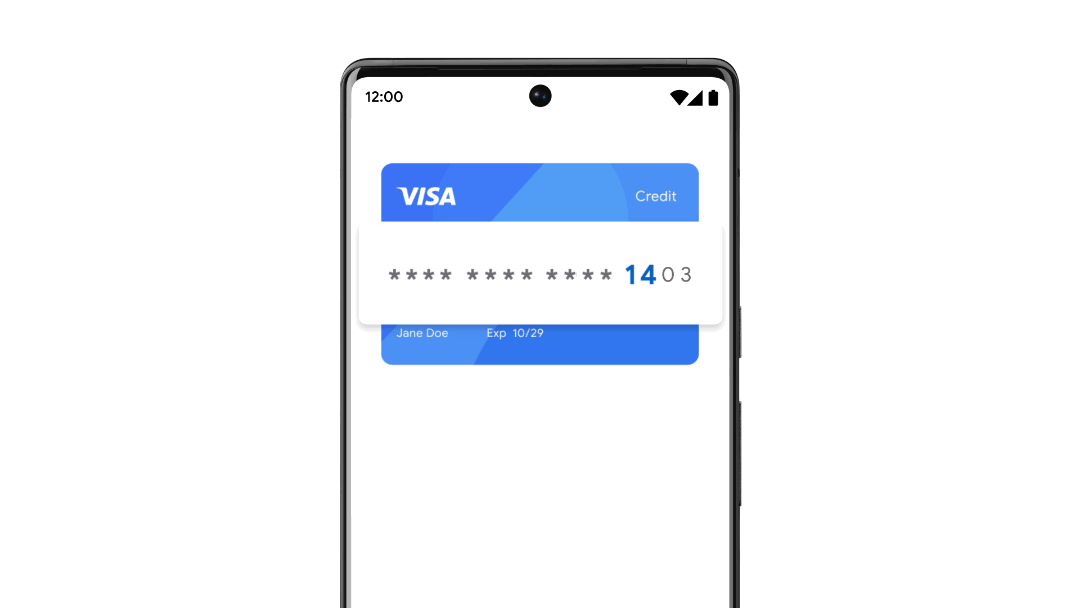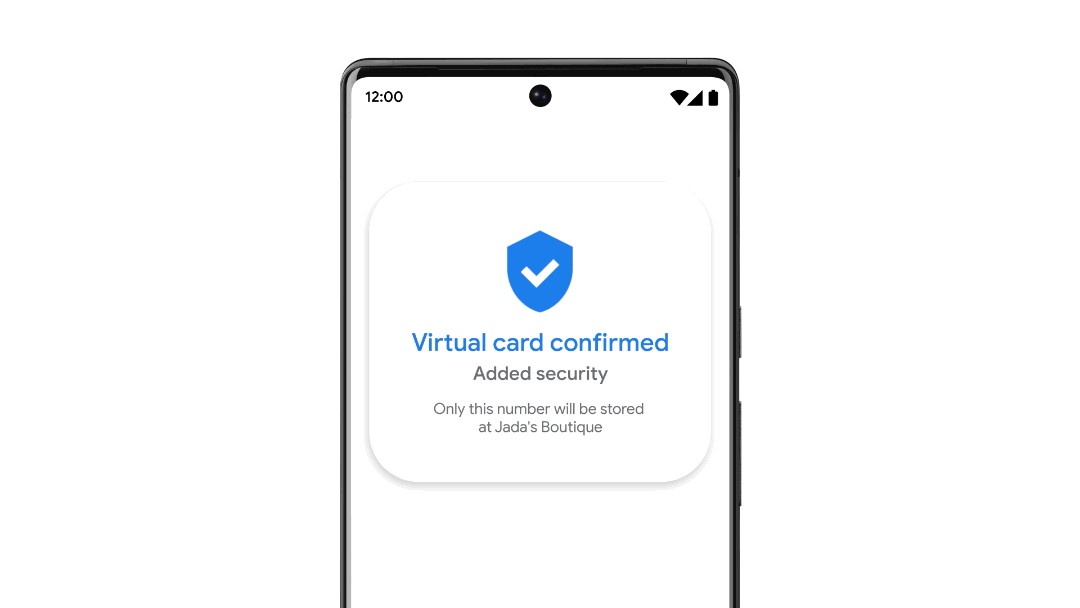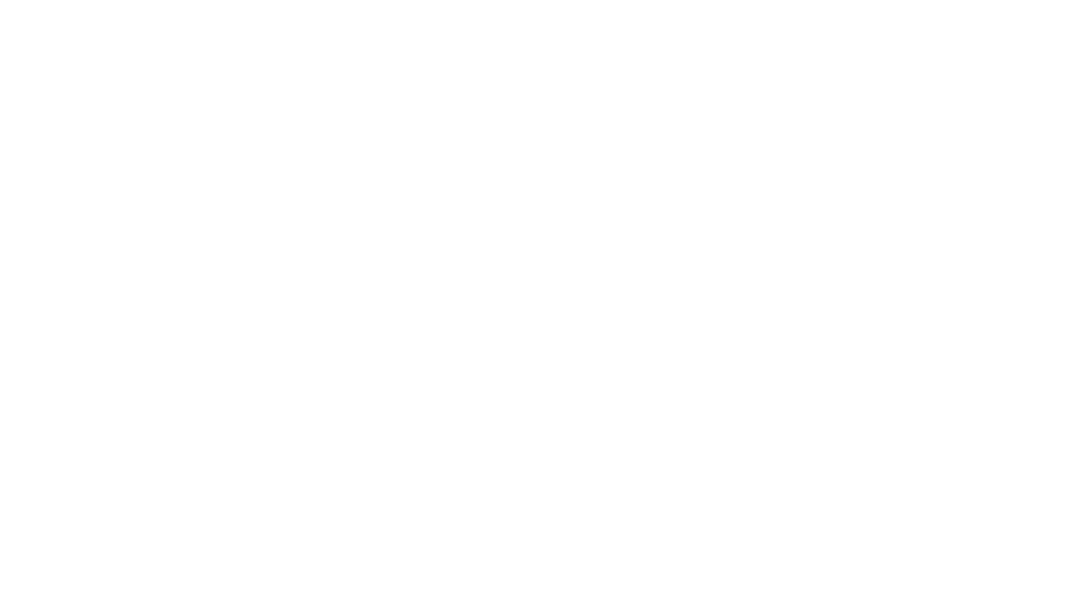
버추얼카드는 2022년 여름부터 미국에서 이용 가능하게 되며 비자나 아메리칸익스프레스, 캐피털원, 마스터카드 신용카드에 대응한다고 한다. 관련 내용은 이곳에서 확인할 수 있다.
구글은 또 구글 I/O 2022 기간 중 자연어 처리 AI인 람다2(LaMDA 2)와 데모 앱인 AI 테스트 키친(AI Test Kitchen)도 발표했다.
AI 테스트 키친은 구글 대화 특화형 AI인 람다(Language Model for Dialogue Applications) 2세대를 스마트폰용 데모로 한 것. 사이트를 통해 애니메이션으로 공개된 3가지 기능(Imagine It, List It, Talk About It)을 경험해볼 수 있다.
이메지잇은 사용자가 현실 또는 가상 장소를 제시하고 람다가 이를 설명하는 모드다. 예를 들어 바다 가장 깊은 곳을 입력하면 람다는 당신은 바다 바닥에 있다며 머리 위에는 거대한 바다뱀이 수영하고 있다는 식으로 대화를 펼칠 수 있는 옵션 4개가 나타난다. 옵션 중 그 밖에 다른 생물이 있냐는 걸 선택하면 람다는 주위에는 거대한 빛나는 해파리가 보인다고 답한다.

상상력이 풍부한 아이와 바다 바닥에 대해 얘기를 하는 것 같은 자연스러운 대답이지만 이는 사람이 미리 수작업으로 회답문을 프로그래밍한 건 아니다. 구글 순다르 피차이 CEO에 따르면 토성 고리와 아이스크림으로 만들어진 행성에 대해 비현실적인 걸 포함한 모든 상황에 대해 얘기할 수도 있다고 한다.
리스트잇은 특정 작업을 달성하기 위한 절차와 아이디어를 나열하는 기능이다. 여기에 채소밭을 만든다고 입력하면 어떤 스타일로 할지 선택하고 장소와 흙을 어떻게 할지, 씨를 뿌리거나 모종을 사는 등 순서가 리스트화된다.
마지막으로 토크어바웃잇은 특정 화제에 대해 문장으로 개방적으로 얘기하는 모드다. 아직 몇 가지 화제 밖에 대응하고 있지 않다. 개 밴드명을 생각하자는 말을 입력하면 람다가 명칭을 제안한다. 이 이름을 생각한 이유를 물으면 람다가 답을 하는 등 자연스럽고 고도 대화라는 인상을 준다.
순차르 피차이 CEO는 AI 테스트 키친과 람다 전망에 대해 이런 언어 모델을 실용화할 때에는 과제가 있다며 답이 생성될 수도 있고 앱에서 피드백을 수집하고 문제를 보고하는데 도움을 줄 수 있다고 말한다. 이를 위해 인권 전문가까지 폭넓은 관계자와 피드백을 신중하게 평가하면서 프로세스를 반복해나갈 예정이다.
한편 구글이 제공하는 번역 서비스인 구글 번역에 새롭게 24개 언어 지원을 추가했다. 이에 따라 구글 번역이 지원하는 언어 수는 133개에 이른다.
구글에 따르면 이번에 새롭게 지원된 언어 24개를 이용하는 화자는 전 세계에서 3억 명 이상에 달한다고 한다. 이번에 지원된 언어로는 인도 북동부에서 80만 명이 사용하는 미조어와 중앙아프리카 전체에서 4,500만 명 이상이 사용하는 링가라어 등이 있다. 더구나 이번 업데이트에선 미국 원주민이 사용하는 케추어어, 과라니어, 아이마라어, 영어 방언인 시에라리온 크리오어도 처음 지원된다.
구글 번역이 24개 언어를 새로 지원할 수 있게 된 이유는 딥러닝과 자연어 처리를 통합해 기계번역 기술이 최근 몇 년간 큰 발전을 이뤘기 때문이다. 이런 기계번역 기술에서 병목이 되는 건 마이너 언어에선 디지털화된 텍스트 데이터가 한정되어 있다는 점이다. 또 기계 번역 모델은 대개 번역된 병렬 텍스트를 많이 사용해 번역 방법을 학습해야 한다. 하지만 앞서 언급한 데이터 부족으로 인해 기계번역 모델은 제한된 양 단일 언어 텍스트에서 번역 방법을 학습해야 한다.
또 데이터가 부족한 마이너 언어 텍스트 데이터를 자동 수집하는 건 어렵다고 한다. 언어 특정을 실시하는 라이브러리(LangID) 등은 메이저 언어에선 잘 기능하지만 마이너 언어에선 실패하는 경우가 많다고 한다. 더구나 인터넷상에서 수집된 데이터 세트에는 사용 가능한 데이터보다 많은 노이즈가 포함되는 경우가 많기 때문에 마이너 언어를 올바르게 번역할 수 있는 모델 구축은 어려워지고 있다.
이 때문에 구글은 LangID 모델을 MASS 작업으로 보완하고 노이즈가 많은 데이터를 일반화하는데 성공했다. MASS는 토큰시퀀스를 무작위로 제거해 일부 입력을 문자화하고 이런 시퀀스를 예측해 모델을 학습한다. 이렇게 하면 데이터세트가 적은 사소한 언어 유사 언어 집단을 식별할 수 있다.
이를 구사한 게 구글 제로 리소스 번역 모델이다. 단일 언어 텍스트 데이터 세트 뿐 아니라 수백만 개 주요 언어로 이뤄진 병렬 텍스트 데이터를 포함해 번역 작업을 학습해 1,000개 이상 언어로 사용 가능한 데이터를 함께 학습하는 단일 거대 번역 모델이 되고 있다. 구글 제로 리소스 번역 모델에는 학습할 때 모델이 보는 입력에 대해 어떤 언어로 출력해야 하는지를 나타내는 특별한 토큰이 있다. 구글은 단일 언어 MASS 작업과 번역 작업 모두에 동일 토큰을 이용해 특정 토큰(예 translate_to_french)에 대해 영어 소스를 불어로 번역하는 작업 소스와 문화화된 불어로 유창하게 번역하는 MASS 태스크 둘 다 실행 가능하다. 구글은 이 간단한 단계만으로 놀라울 만큼 번역 정확도가 향상됐다고 밝혔다.
구글 제로 리소스 번역을 이용하면 마이너 언어도 자연어에서 다른 자연어로 기계 번역된 텍스트 품질을 평가하기 위한 알고리즘인 BLEU 점수가 중간 품질, 다른 알고리즘(ChrF)이라면 고품질 점수를 보였다고 한다. 관련 내용은 이곳에서 확인할 수 있다.