12월 11일 구글이 정보 정리 AI 기능인 딥리서치(Deep Research)를 발표했다. 딥리서치는 사용자 지시에 따라 문제 해결에 도움되는 정보를 인터넷에서 수집해주는 기능으로 수집한 정보를 이해하기 쉬운 보고서로 정리해 출력해준다.
인터넷상에는 문제 해결에 도움되는 정보가 수많이 존재하지만 인간이 직접 목적에 맞는 정보를 찾아 정리하는 데는 오랜 시간이 걸린다. 딥리서치는 구글 유료 AI 서비스인 제미나이 어드밴스드(Gemini Advanced)에 추가된 기능으로 사용자 지시에 따라 정보를 검색해 보고서로 정리해준다.
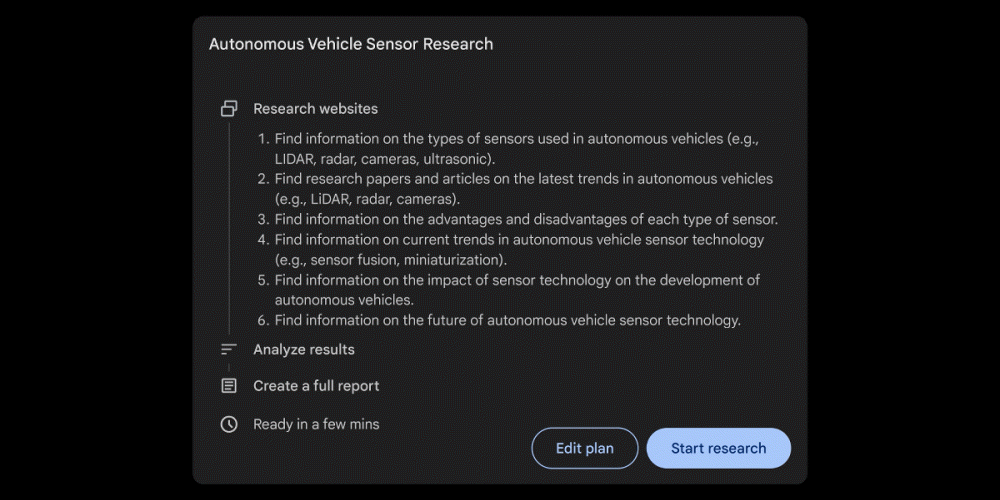
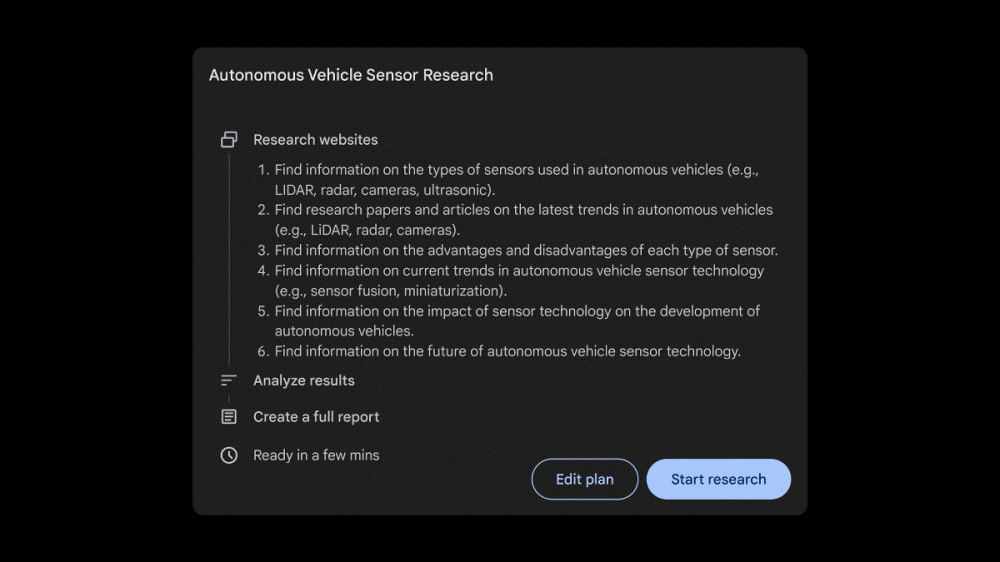
딥리서치 사용 예시를 보면 먼저 로봇공학에 관한 기사를 쓰고 싶으니 자율주행차 센서 트렌드에 대해 정리해달라고 요청하면 딥리서치는 자율주행차 센서 종류에 관한 정보 수집, 센서 트렌드에 관한 논문 및 기사 찾기 등 정보 수집 계획을 세워준다. 정보 수집을 실행하려면 스타트 리서치(Start research)를 클릭하면 된다. 몇 분 기다리면 수집된 정보를 정리한 보고서가 출력된다. 이 보고서는 구글 문서에 저장할 수도 있다. 보고서에는 정보를 이해하기 쉽게 정리한 표도 포함되어 있다. 정보 출처 웹페이지에 대한 링크도 표시된다. 더불어 추가 정보를 수집하도록 요청할 수도 있다.
딥리서치 정보 수집 및 보고서 작성에는 제미나이 1.5 프로가 사용되고 있다고 한다. 한 AI 연구자는 딥리서치를 시험 사용한 결과 거의 모든 주제에 대해 우수한 초기 보고서를 작성해줬지만 일부 학술지는 무료로 접근할 수 없어 한계도 있다고 언급했다.
참고로 딥리서치는 현재 제미나이 어드밴스드 영어 버전에서만 이용 가능하다. 관련 내용은 이곳에서 확인할 수 있다.

한편 지난 5월 구글이 발표한 6세대 TPU인 트릴리움(Trillium(v6e))이 구글 클라우드 사용자를 위해 일반 제공됐다. 트릴리움은 이전 모델과 비교해 성능은 4배, 에너지 효율은 67% 향상됐다.
트릴리움은 지난 5월 구글I/O 2024에서 발표된 제6세대 TPU로 이전 세대 TPU v5e와 비교해 칩당 피크 성능이 4.7배로 고대역폭 메모리(HBM) 용량과 대역폭이 2배로 증가하는 등 다양한 진화를 이뤘다.
구글은 트릴리움은 구글 클라우드 AI 하이퍼컴퓨터 주요 구성 요소이며 성능에 최적화된 하드웨어, 오픈소스 소프트웨어, ML 프레임워크를 채택한 획기적인 슈퍼컴퓨터 아키텍처라고 소개했다.
이 트릴리움이 일반 사용자에게도 제공되기 시작했다. 구글은 트릴리움을 사용해 AI 트레이닝 워크로드 확장, 고밀도 모델과 MoE(Mixture of Experts) 모델을 포함한 LLM 트레이닝, 추론 성능과 컬렉션 스케줄링 등 폭넓은 워크로드에서 우수한 성능을 누릴 수 있다고 어필하고 있다.
AI 트레이닝 워크로드 확장 예로 gpt3-175b 모델 사전 학습 스케일링 효율성이 제시됐다. 트릴리움은 1개 포드당 256개의 칩이 있으며 이를 12개 사용할 경우 스케일링 효율성은 최대 99%를 달성했다. 24개 사용 시에도 94%의 효율성을 유지하고 있다.
Llama-2-70B 모델 트레이닝에서는 4 슬라이스 트릴리움-256 칩 포드부터 36 슬라이스 트릴리움-256 칩 포드까지 99% 스케일링 효율성으로 거의 직선적인 스케일링을 달성한 게 입증됐다. 또 동등 규모 이전 모델인 v5p와 비교했을 때에도 트릴리움은 더 뛰어난 스케일링 효율성을 보여준다.
이 트릴리움은 같은 날 발표된 제미나이 2.0 트레이닝에도 사용되고 있다. 제미나이와 같은 대규모 언어 모델(LLM)은 수십억 개에 이르는 파라미터를 갖고 있어 트레이닝이 복잡하고 막대한 계산 능력을 필요로 한다. 구글에 따르면 이전 모델인 v5e와 비교할 때 트릴리움은 고밀도 LLM인 gpt3-175b에 대해 3.24배, Llama-2-70b에 대해 최대 4배 빠른 트레이닝을 실현한다고 한다.
또 MoE라는 기계 학습 기법으로 LLM을 학습하는 게 일반화되고 있는데 트레이닝 중 관리 및 조정이 더 복잡하다고 한다. 트릴리움은 이런 복잡성을 완화하고 v5e와 비교해 MoE 모델 트레이닝을 최대 3.8배 고속화한다.
더불어 트릴리움은 v5e에 비해 3배의 호스트 DRAM을 제공한다. 구글은 이는 계산 일부를 호스트에 오프로드하고 스케일 시 성능과 처리량을 최대화하는 데 도움이 된다고 언급했다.
추론 시 멀티스텝 추론 중요성이 높아짐에 따라 트릴리움은 추론 워크로드에서 크게 진보했으며 v5e와 비교해 스테이블 디퓨전 XL 상대 추론 처리량이 3배 이상, Llama2-70B 상대 추론 처리량이 거의 2배 향상됐다. 오프라인 및 서버 추론 양쪽 사용 사례에서 최고의 성능을 발휘하는 것도 특징으로, 오프라인 추론 시 상대 처리량이 v5e 3.11배, 서버 추론 시 2.9배가 된다.
1달러당 비용 성능도 높아 v5e와 비교해 1달러당 최대 2.1배 성능 향상, v5p와 비교해 1달러당 최대 2.5배 성능 향상을 실현했다. 트릴리움으로 이미지 1,000장을 생성하는 비용은 오프라인 추론 시 v5e보다 27% 낮고, 서버 추론 시 v5e보다 22% 낮다고 한다. 관련 내용은 이곳에서 확인할 수 있다.