
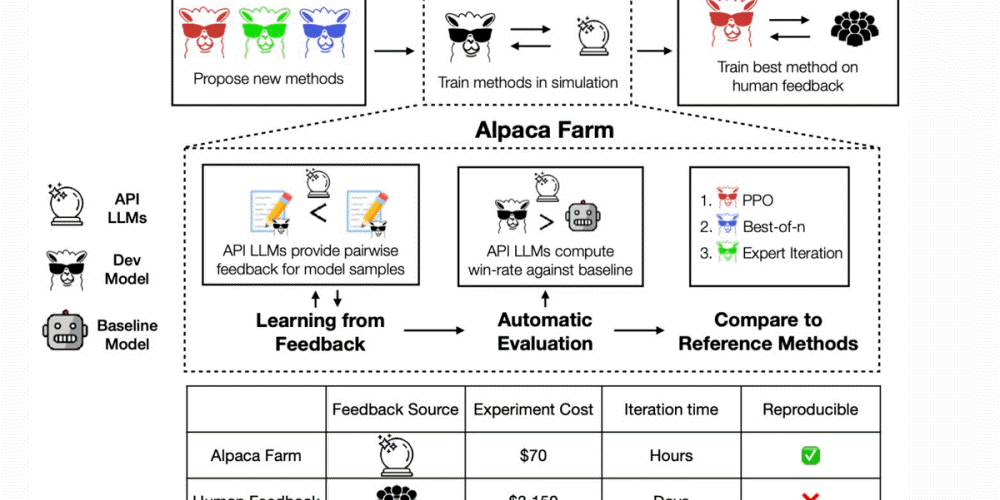
대규모 언어 모델 학습에 있어선 실제 인간에 의한 평가를 모델 출력에 반영하는 RLHF(Reinforcement Learning from Human Feedback)가 이뤄진다. 하지만 RLHF는 실제 인간을 사용하기 때문에 비용이 많이 들거나 피드백을 회수하는데 시간이 걸리는 등 단점이 존재했다. 스탠포드대학 연구팀이 개발한 알파카팜(AlpacaFarm)은 인간이 어떤 평가를 들려주는지 시뮬레이션해 저렴하고 빠른 속도로 RLHF를 진행하는 도구다.
대규모 언어 모델 학습은 대량 텍스트로 모델을 학습(Pretrained LLM)하고 다음에 본이 되는 데이터를 이용해 교사 첨부 파일 튜닝을 실시해 SFT 모델을 만든다. 이에 더 정확도를 높일 때 사용하는 게 RLHF다.
알파카팜에는 모델 응답에 평가를 제공하고 기준 모델과 새 모델 비교 평가, 참조 구현과 비교 제공이라는 3가지 기능이 있다. 모델 응답 평가에 대해 인간과 알파카팜 일치률은 기준이 되는 모델보다 평가 대상 모델 응답이 뛰어나다고 판정되는 비율. 이를 보면 인간에 의한 평가가 낮은 경우에는 알파카팜 시뮬레이션에서도 평가가 낮아진다. 반대로 인간이 높이 평가하는 모델을 알파카팜도 높이 평가하고 있다. 실제 인간에게 평가받는 경우보다 45분의 1 비용과 훨씬 짧은 시간에 동등한 평가를 할 수 있다고 한다.
또 알파카팜에 의한 시뮬레이션에선 실제 인간을 이용한 RLHF를 실시한 경우와 마찬가지로 과잉 최적화 등 현상이 발생한다. 알파카팜 2번째 기능인 모델끼리 평가에선 복수 공개 데이터세트를 바탕으로 새로운 평가용 데이터세트를 작성했다고 한다. 알파카 7B 데모 버전이 공개됐을 때 모은 실제 사용 사례 데이터와 가능하면 비슷한 세트가 되도록 조정했다고 한다. 실제 사용 사례 프롬프트와 새로운 평가용 프롬프트에서 다빈치003 모델과 RLHF 모델에 대한 응답을 생성해 어떤 게 높은 평가 응답을 생성할 수 있는지 시뮬레이션했다. 그 결과 실제로 이뤄지는 단순한 명령 퍼포먼스를 충분히 근사할 수 있다는 것으로 나타났다.
알파카팜 마지막 특징은 일반 학습 알고리즘 3개(PPO, Best-of-n, Expert Iteration)를 참고 구현으로 탑재하고 있다는 것이다. 알파카팜 개발팀은 이들 3가지 RLHF 모델과 기타 모델에서 알파카를 다빈치003과 승률을 비교했다. 그 결과 인간에 의한 평가에선 PPO가 챗GPT를 웃도는 평가를 얻을 수 있었다고 한다. 관련 내용은 이곳에서 확인할 수 있다.























