챗GPT와 빙챗 배경에 있는 대규모 언어 모델 대부분은 구글이 개발한 신경망 아키텍처인 트랜스포머(Transformer)를 채용하고 있다. 이런 트랜스포머 키가 되는 게 셀프-어텐션(Self-Attention)이라는 시스템이다. 이런 셀프-어텐션을 시각화하기 위한 도구인 어텐션 비즈(Attention Viz)를 하버드대학과 구글 공동 연구팀이 발표했다.
자연어 처리를 딥러닝으로 실시하면 지금까지는 RNN을 이용했다. 하지만 2017년 6월 구글이 논문(Attention is All You Need)에서 어텐션이라는 개념을 도입한 시스템을 발표해 자연어 처리 모델 점수를 크게 올렸다. 어텐션 시스템은 RNN보다 성능이 높을 뿐 아니라 GPU 연산 효율이 좋기 때문에 학습이 빠르고 또 RNN보다 취급이 간단하기 때문에 대규모 언어 모델에 있어 어텐션은 필수적인 기구가 됐다.
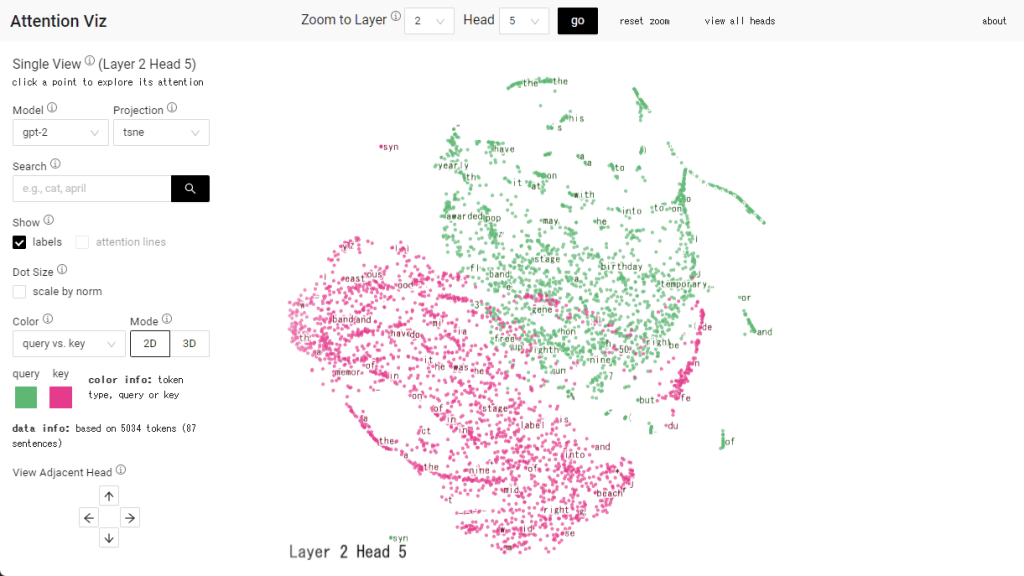
트랜스포머는 입력을 처리하는 인코더 부분과 출력 결과를 처리하는 디코더 부분으로 나뉘며 둘다 셀프-어텐션이라는 시스템에 채용되고 있다. 이 셀프-어텐션은 한 문장 토큰이 다른 단어와 얼마나 관련되어 있는지를 계산한다. 토큰간 연관성을 계산하기 위해 인코더 셀프-어텐션은 각 입력 요소에서 쿼리와 키라는 2가지 값을 계산한다.
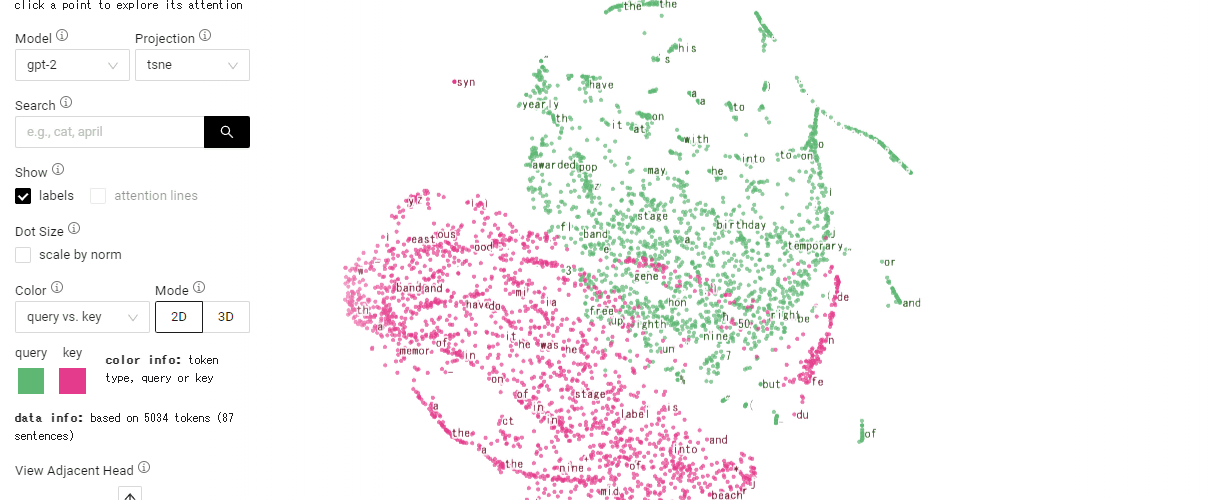
예를 들어 1개 문장(the sky is blue)은 4개 토큰(the, sky, is, blue)으로 분해할 수 있다. 각 쿼리와 키 행렬을 계산하고 좌표를 표시하면 좌표상에서 각 토큰 거리가 가까우면 관련성이 높고 멀리 있으면 관련성이 낮다. 이렇게 토큰 쿼리와 키를 좌표에 나타내고 시각화한 게 어텐션 비즈다.
데모 사이트에선 논문이나 깃허브에 대한 링크도 볼 수 있다. 또 모델에서 대규모 언어 모델(Vision Transformer (vit), Google Bert, GPT-2)을 선택할 수 있다. 관련 내용은 이곳에서 확인할 수 있다.