
자연어 처리 알고리즘은 단어 순서와 구조 이해에 서투르다. 이 문제를 극복하기 위해 구글은 새로운 데이터세트를 공개했다. 이 데이터세트는 훈련을 실시하면 기계학습 모델의 텍스트 분류 정확도가 50%에서 80%까지 높아진다고 한다.
구글은 기계번역과 음성 인식에서 자연어 처리를 도입하고 있다. 하지만 자연어 처리에서 아무리 최신 알고리즘이라도 뉴욕에서 플로리다로 비행 혹은 플로리다에서 뉴욕으로 출발하는 항공권, 플로리다에서 뉴욕행 항공편 같은 문장의 차이를 인식할 수 없다. 기존 알고리즘의 약점은 의역에 있다는 건 이전부터 연구자들이 지적해온 것이다.
구글은 이 문제를 다양성을 이용해 해결하기 위해 지난 10월 2일 PAWS(Paraphrase Adversaries from Word Scrambling)라는 코퍼스, 말뭉치를 공개했다. PAWS는 영어로만 이뤄져 있지만 구글은 동시에 불어와 스페인어, 독일어, 중국어, 일본어, 한국어를 지원하는 PAWS-X도 공개했다. 의역이 아닌 의역으로 이뤄진 PAWS와 PAWS-X를 이용한 알고리즘이 단어 순서와 구조를 파악해 정확도를 지금까지 50%에서 85∼89%로 증가시켜줄 것이라는 설명이다.
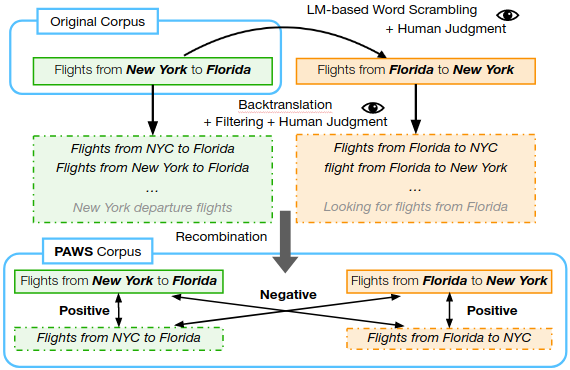
PAWS 데이터세트는 위키피디아나 쿼라 퀘스천 페어(Quora Question Pairs)를 소스로 하는 영어로 인간이 붙인 10만 8,463쌍 단어를 포함하고 있다. 한편 PAWS-X는 인간이 번역한 PAWS 데이터 2만 3,659쌍과 기계번역 학습을 통한 29만 6,406쌍을 포함했다.
구글 측에 따르면 비록 복잡한 맥락 문장을 이해하는 기계학습 모델도 특정 문자 패턴을 배우는 건 어렵다. 새로운 데이터세트는 기계학습 모델이 가진 단어 순서와 구조에 대한 민감도를 측정하기 위한 효과적 수단을 제공할 것이라는 설명이다.
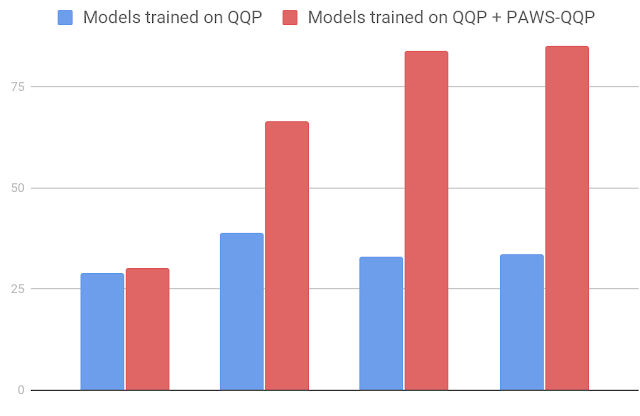
자연어 처리 정확도에 대한 말뭉치 영향을 조사하기 위해 구글은 여러 모델에 대해 학습을 실시했다. 그 중에서도 BERT 모델과 DUUN 모델 두 기준을 비교해 현저하게 개선됐다고 한다. BERT 분류 정확도는 원래 33.5%였지만 PAWS와 PAWS-X 덕에 정확도는 83.1%까지 올라갔다는 것.
구글 측은 이 데이터세트가 문장 구조와 문맥 추출, 쌍 비교 등을 개선하고 다국어 모델 연구 커뮤니티에 큰 진전을 주기를 기대한다고 밝히고 있다. 관련 내용은 이곳에서 확인할 수 있다.




















