코로나19 기간 중에도 넷플릭스 시청자 수는 증가 중이다. 이에 따라 서버 부하도 덩달아 늘어나고 있다. 물론 지역에 따라 1시간 가량 정지 같은 현상이 발생하지만 2020년에는 전 세계적으로 서비스 정지 등을 수반한 대규모 장애는 발생하지 않았다. 이는 우연이 아니라 넷플릭스의 노력이 만들어낸 결과. 넷플릭스는 11월 2일(현지시간) 장애가 발생하면 서비스를 중단하지 않고 트래픽을 관리하는 우선순위를 매긴 부하 분산 구조에 대해 공개했다.
넷플릭스는 원래 중앙집권적인 게 아니라 작은 서비스가 모여 전체를 이루는 마이크로 서비스 형태를 취하고 있다. 이 때문에 일부 서버에서 하드웨어 오류가 발생해도 전체 서비스가 중단될 가능성은 낮아지고 있다. 이를 이용해 항상 장애가 계속 자동 복구되는지 동작 확인을 하고 큰 실패를 막는 카오스 엔지니어링을 채용하고 있는 건 유명한 얘기다.

하지만 시스템 일부가 정지해 다른 부분 트래픽이 증가하는 등 2차 장애도 있을 수 있다. 따라서 넷플릭스는 트래픽 중요도로 나눠 사용자 시청 경험에 직접 영향을 주지 않는 트래픽을 제한해 서비스 중단을 방지하는 방법을 도입했다. 이 중요도 판별을 하는 게 API 게이트웨이 서비스 줄(Zuul)로 소스코드는 깃허브에 공개되어 있다.
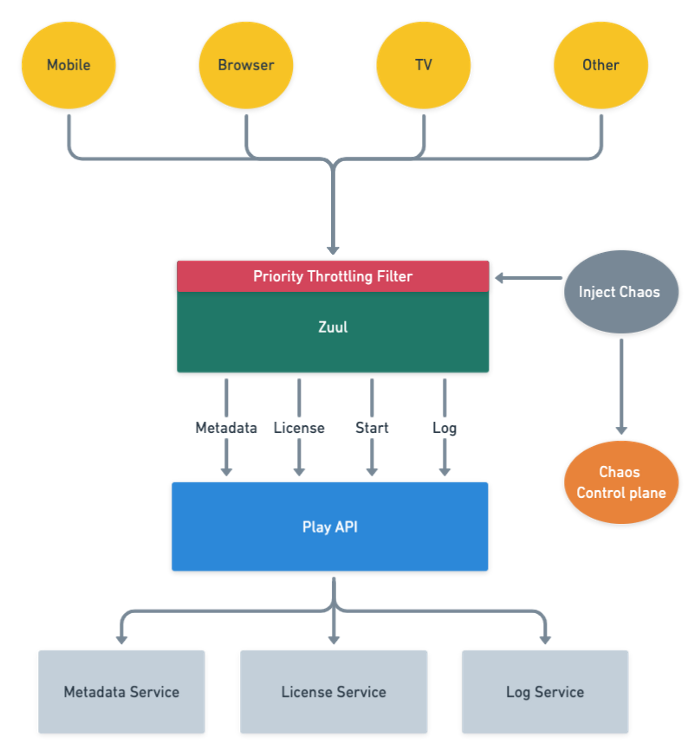
실제로 2020년에도 2019년 발생했던 글로벌 서비스 중단 같은 오류가 발생했음에도 이 구조 덕에 서비스 중단 없이 복구할 수 있었다는 것이다. 넷플릭스는 앞으로도 부하 제한 임계값을 조정하는 등 방식을 계속할 예정이다.
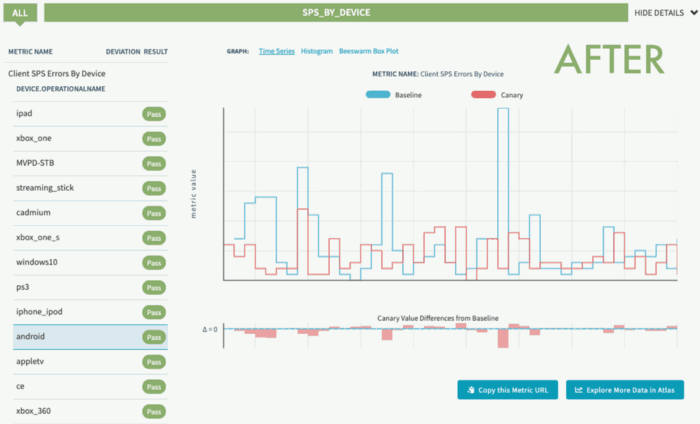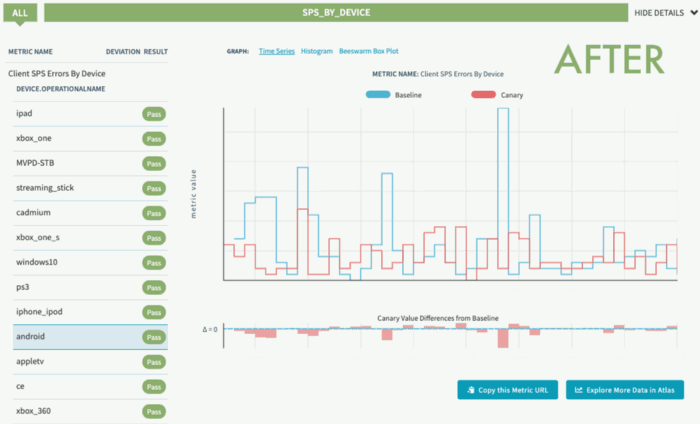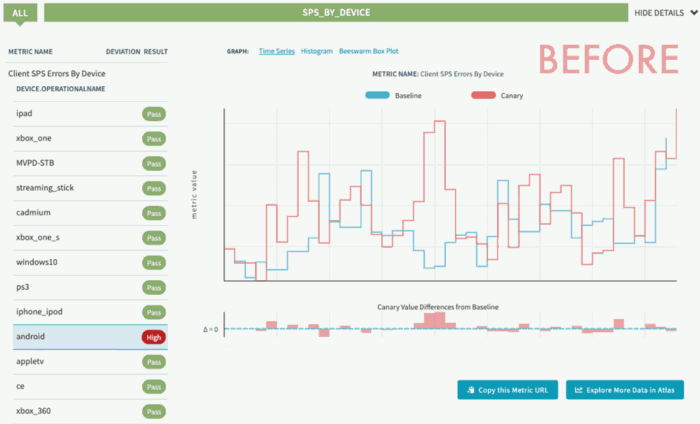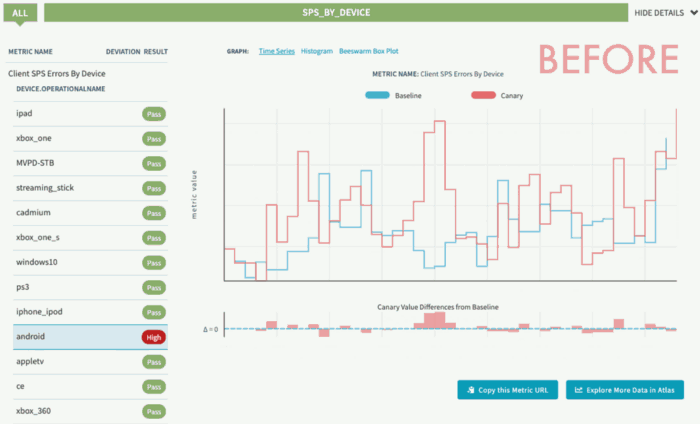
한편 넷플릭스는 지난 2020년 3월에는 유럽에서 비트 전송률 제한도 실시했지만 이는 부하 분산을 위해서가 아니라 유럽 전체에 네트워크를 통한 데이터 용량을 줄이기 위한 것이라고 한다. 관련 내용은 이곳에서 확인할 수 있다.