페이스북 모기업인 메타 내 인공지능 연구 부문인 메타AI(Meta AI)가 구두로 대화하는 걸 거의 실시간으로 번역 가능한 AI를 이용한 음성 번역 시스템을 개발해 오픈소스로 공개하고 있다.
AI를 이용한 음성 번역 시스템은 기본적으로 텍스트를 번역하는데 중점을 뒀다. 하지만 지구에선 3,500종류에 가까운 언어가 있으며 대부분은 표어문자를 갖지 않고 구어로만 취급된다. 이 때문에 번역 AI 모델을 학습시키는데 필요한 대량 텍스트 데이터를 준비할 수 없는 언어도 다수 존재한다.
이 문제를 해결하기 위해 메타는 중국 푸젠성에서 사용되는 푸젠어를 위한 첫 AI를 이용한 음성 번역 시스템을 구축했다. 푸젠어는 주로 구두로 사용되는 언어이며 중국 푸젠성에서 널리 사용되고 있지만 표준 표어 문자를 갖고 있지 않기 때문에 텍스트 데이터를 준비하는 게 어려운 언어이기도 하다.
푸젠어는 중국 푸젠성 뿐 아니라 싱가포르와 필리핀, 대만, 말레이시아 등 지역에서도 사용되는 언어로 전 세계 4,600만 명 가까이가 말한다. 이 푸젠어를 위한 AI 번역 시스템에 대해 메타는 구두 언어 수백 개를 실시간으로 번역하는 걸 목표로 하는 유니버설 스피치 번역(Universal Speech Translator) 프로젝트 일부이며 새로운 AI 방법을 개발하고 결국 푸젠어 이외 많은 언어에서 실시간 언어에서 다른 언어로 번역갈 수 있게 하는 걸 목표로 하고 있다.
물론 아직 메타 푸젠어 AI 번역 시스템은 개발 중이며 한 번에 한 문장만 번역할 수 있다. 하지만 메타는 언어간 동시 번역이 가능해지는 미래에 대한 첫 걸음이라고 앞으로의 발전에 기대감을 나타냈다.
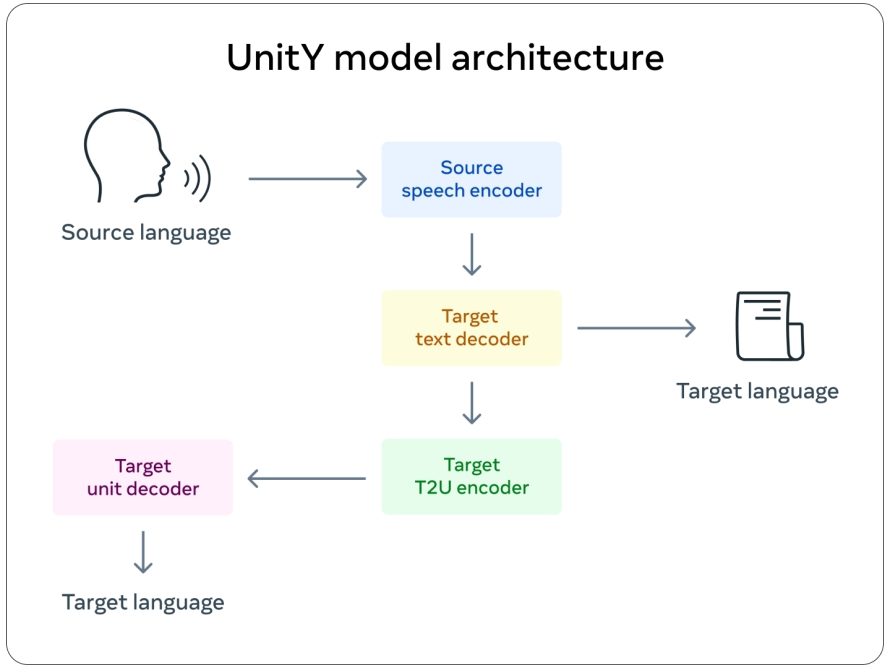
메타는 또 푸젠어 AI 번역 시스템 발표와 동시에 레이저(LASER)라는 혁신적 자연어 처리 툴킷으로 개발된 음성에서 음성으로의 번역 시스템을 구축하는데 도움이 되는 대규모 데이터세트 스피치매트릭스(SpeechMatrix)도 출시됐다. 스피치매트릭스는 다른 연구자가 구두 언어에서 다른 언어로 음성 기반으로 번역할 수 있는 번역 시스템을 개발할 수 있게 해주는 도구로 136개 언어쌍과 41만 8,000시간 분량 음성 데이터로 구성된 데이터세트다.
스피치매트릭스는 인간 없는 학습을 기반으로 하며 인간 주석 없이 고품질 음성에서 음성으로의 번역이 가능한 AI 모델을 구축할 수 있기 때문에 보통 시스템을 교육하는데 필요한 라벨이 있는 학습 데이터가 없는 언어로 번역 시스템을 구축할 수 있다. 또 메타는 푸젠어 번역 모델, 평가 데이터세트, 연구 논문을 오픈소스로 공개하고 있다. 관련 내용은 이곳에서 확인할 수 있다.