라이스 대학 디지털 신호 처리 그룹이 AI 훈련에는 방대한 데이터가 필요하지만 이 데이터에 AI가 생성한 데이터를 사용하면 향후 심각한 악영향이 발생할 수 있다는 연구 결과를 발표했다.
GPT-4나 스테이블디퓨전 등 생성형 AI 훈련에는 방대한 데이터가 필요하며 개발자는 이미 데이터 공급 한계에 직면하고 있다. 이런 상황에서 AI가 생성한 데이터 사용이 선택지로 떠오르고 있지만 라이스 대학 연구팀은 이게 위험한 결과를 초래할 수 있다고 경고하고 있다.
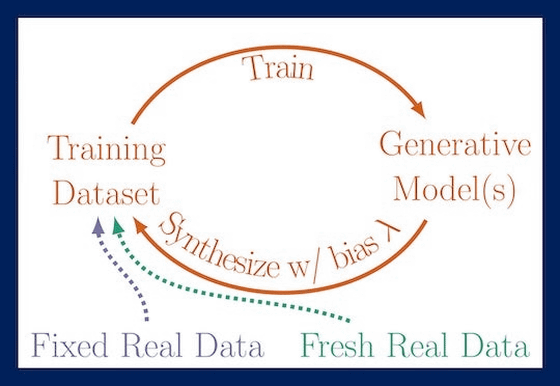
연구팀은 생성 AI 모델 훈련에 AI가 생성한 데이터를 사용하는 장기적인 영향에 초점을 맞춘 연구를 수행했다. 그 결과 AI가 자신이 생성한 데이터로부터 학습하는 자기 소비 훈련을 반복하면 출력 결과 품질과 다양성이 점차 저하되는 것으로 밝혀졌다. 연구팀은 이 현상을 MAD(Model Autophagy Disorder)라고 명명했다.
연구팀은 MAD를 검증하기 위해 이전 세대 출력 결과만으로 훈련, 이전 세대 출력 결과와 고정된 실제 데이터를 조합한 데이터세트로 훈련, 이전 세대 출력 결과와 새로운 실제 데이터를 조합한 데이터세트로 훈련이라는 3가지 패턴을 준비했다.
그 결과 새로운 실제 데이터를 얻을 수 없는 2가지 패턴에서 모델 출력이 점차 왜곡되고 출력 결과에서 품질과 다양성이 상실되는 것으로 밝혀졌다. 예를 들어 인간 얼굴을 생성한 경우 세대(t)를 거듭할수록 얼굴에 격자 모양 상처와 같은 노이즈가 생겼다.
다음으로 연구팀은 이전 세대 AI 출력 결과에서 자기 소비 훈련용 고품질 데이터를 선별하는 체리 피킹을 재현하는 실험을 수행했다. 먼저 체리 피킹을 하지 않고 고정된 실제 데이터와 이전 세대가 생성한 데이터로 훈련을 반복한 AI 각 세대에 0부터 9까지의 숫자를 출력하게 한 결과 5세대부터 문자가 무너져 원형을 알아볼 수 없게 되고 20세대가 되면 단순한 얼룩 같은 결과가 출력되어 품질이 급격히 저하되는 걸 알 수 있다.
반면 체리 피킹을 통해 고품질 결과를 우선적으로 포함하는 데이터세트로 훈련을 반복한 AI에 출력하게 한 결과 오랜 세대에 걸쳐 고품질 데이터가 유지되어 20세대에 이르러서도 대부분 제대로 읽을 수 있는 숫자가 되고 있다. 다만 모든 세대에서 출력 결과가 거의 같은 형태가 되어 다양성이 크게 상실된 걸 알 수 있다.
연구팀은 MAD가 여러 세대에 걸쳐 제어되지 않은 채 방치될 경우 인터넷 전체 데이터 품질과 다양성이 손상될 가능성이 있다. AI 자식장애로 인해 예기치 않은 결과가 가까운 미래에 의도치 않게 일어나는 건 피할 수 없을 것이라고 경고했다. 관련 내용은 이곳에서 확인할 수 있다.