


스펙어규먼트(SpecAugment)는 구글이 언어 모델을 이용하지 않고 자동으로 음성을 인식할 수 있게 해줄 수 있게 개발한 기술이다.
구글은 클라우드 스피치투텍스트(Cloud Speech-to-Text)처럼 음성을 자동 인식해 텍스트로 변환하는 자동 음성 인식 기술을 연구하고 있다. 앞서 발혔듯 스펙어규먼트는 언어 모델을 이용하지 않은 채 자동으로 음성을 인식하는 모델 성능을 끌어올려준다.

언어 모델은 언어에서 단어와 단어 관계를 수학적으로 나타낸 것이다. 원래 그냥 소리일 뿐인 음성을 단어 다음에 어떤 단어가 오는지 학습해 의미 있는 문장으로 변환할 수 있는 것이다. 따라서 자동 음성 인식을 가능하게 해주는 AI는 언어 모델에 따라 훈련을 진행해야 한다.
구글 연구팀이 발표한 스펙어규먼트는 언어 모델 도움 없이 기존 방법보다 정확도가 웃도는 자동 음성 인식 모델을 구축할 수 있게 해준다. 기존 자동 음성 인식 모델은 음성 데이터를 스펙트럼 형태로 시각적 표현으로 변환한 다음 네트워크 모델에 입력한다. 인식 처리는 스펙트럼에서 이뤄지지만 제공 데이터 자체는 대량 음성 데이터를 필요로 하며 방대한 연산 비용이 필요하다.

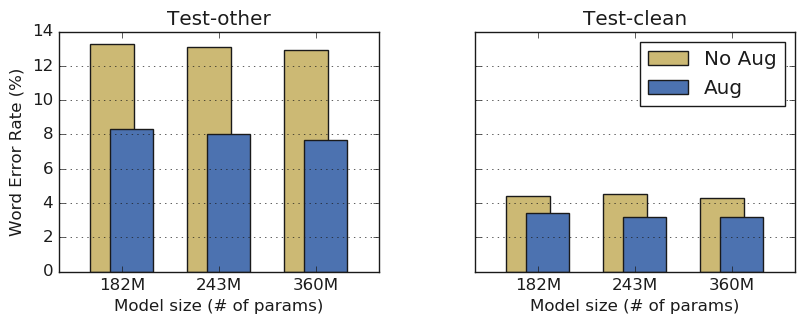
스펙어규먼트는 스펙트럼 데이터를 직접 편집해 마스크를 걸어 스펙트럼 데이터 증강을 실시한다. 이를 통해 모델의 지나친 학습을 방지할 수 있고 언어 모델 지원 없이도 기존 모델보다 높은 정밀도로 음성 인식이 가능하게 된다고 한다. 기존 자동 음성 인식 모델의 오인식률은 잡신호가 음성이라면 12∼14%, 잡신호가 적은 음성이라면 4∼5% 정도다. 스펙어규먼트를 이용한 자동 음성 인식 모델은 시끄러운 음성의 경우 8% 전후, 잡신호가 적은 음성이라면 3% 정도에 불과한 오인식률 저하 그러니까 정확도가 높아진다.
이런 기술로 지원하는 자동 음성 인식 모델이라면 이메일 받아쓰기 모드로 이용하거나 스마트 스피커에 탑재한 대화형 AI 음성을 텍스트로 변환하는 등 활용도를 기대할 수 있다. 오인식률이 떨어지면 실제 손가락으로 타이핑을 하는 것보다 음성으로 빠른 입력을 하는 시대가 가능하게 될지도 모른다. 관련 내용은 이곳에서 확인할 수 있다.




