

중국 알리바바 그룹이 개발한 대규모 언어 모델(LLM) Qwen 연구팀이 코드 생성 및 보완, 수학적 추론 작업에 특화된 LLM인 Qwen2.5-Coder 새 모델을 11월 12일 공개했다. Qwen2.5-Coder 코딩 기능은 GPT-4o에 필적하며 파라미터 수는 최대 320억 개로 M2를 탑재한 맥북 프로에서도 실행 가능하다는 보고가 있다.
Qwen2.5-Coder는 2024년 10월 기술 보고서가 발표됐으며 이때 파라미터 수가 15억(1.5B)과 70억(7B)인 모델이 오픈 소스로 공개됐다. 이번에는 5억(0.5B), 30억(3B), 140억(14B), 320억(32B) 파라미터를 가진 새로운 4개 모델이 오픈 소스로 공개됐다.
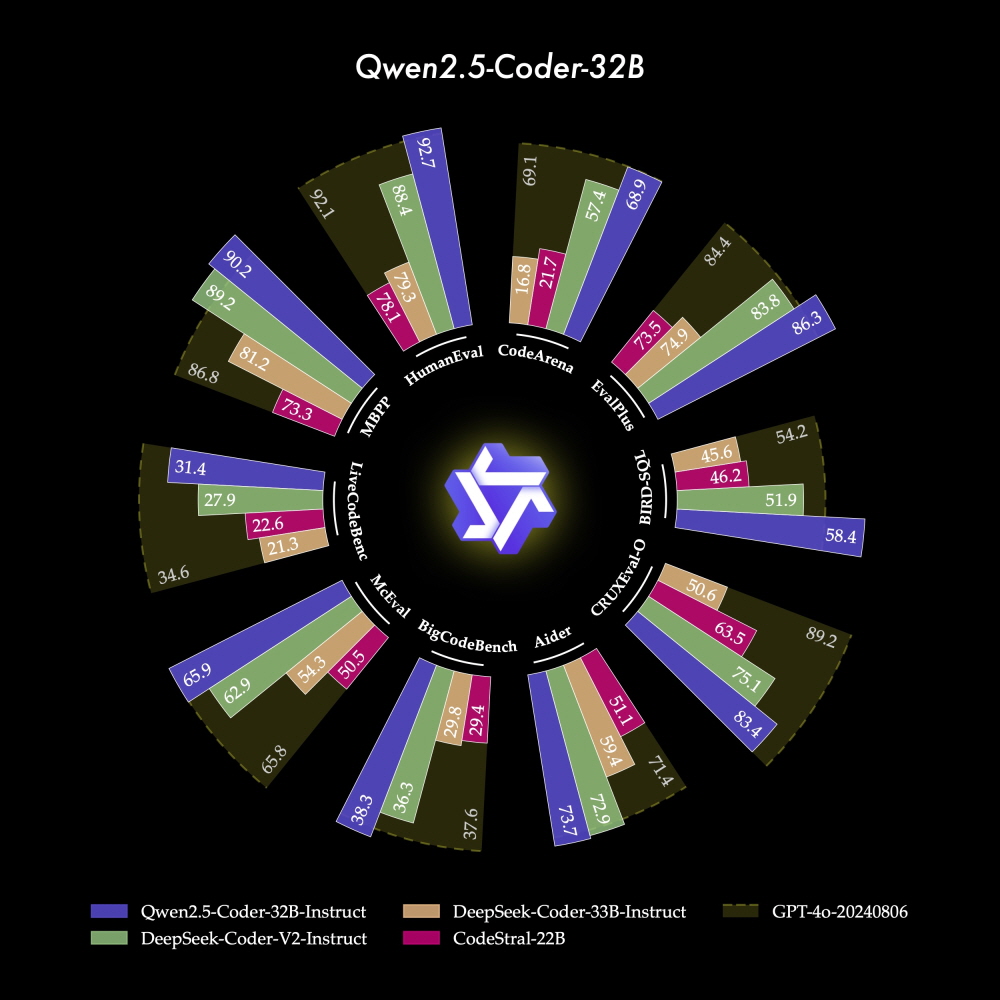
Qwen 연구팀은 플래그십 모델인 Qwen2.5-Coder-32B-Instruct가 코드 생성 벤치마크(EvalPlus, LiveCodeBench, BigCodeBench)에서 GPT-4o와 비슷한 성능을 보였다고 강조하고 있다. 코드 수정 측면에서도 Qwen2.5-Coder-32B-Instruct가 에이더(Aider) 벤치마크에서 GPT-4o와 동일한 성능을 보였다. 연구팀은 코드 실행 프로세스를 학습해 모델 입출력을 정확히 예측하는 코드 추론에서도 Qwen2.5-Coder-32B-Instruct가 뛰어난 성능을 보였다고 주장했다.
Qwen2.5-Coder-32B-Instruct는 40개 이상 프로그래밍 언어에서 우수한 성능을 보였으며 다국어 코딩 벤치마크인 McEval에서 65.9점을 얻었다고 한다. 또 다국어 코드 수정 벤치마크(MdEval)에서는 Qwen2.5-Coder-32B-Instruct가 75.2점을 기록하며 모든 오픈 소스 모델 중 1위를 차지했다고 연구팀은 보고하고 있다.
그리고 연구팀은 Qwen2.5-Coder-32B-Instruct가 인간 선호도와 얼마나 일치하는지 평가하기 위해 코드 아레나(Code Arena)라는 내부 주석이 달린 코드 선호도 평가 벤치마크를 구축했다. 이 벤치마크는 아레나 하드(Arena Hard)와 유사한 형태라고 한다. 평가 결과 Qwen2.5-Coder-32B-Instruct는 인간 선호도와 일치하는 데 있어 우수한 성과를 보였다고 연구팀은 밝혔다.
연구팀에 따르면 이 코드 아레나 결과는 Qwen2.5-Coder-32B-Instruct가 인간 프로그래밍 선호도와 기대에 부합하는 출력을 생성할 수 있음을 의미한다고 한다. 다시 말해 실제 개발 현장에서 Qwen2.5-Coder-32B-Instruct가 더 실용적이고 인간에게 유용한 제안이나 코드를 생성할 가능성이 있다는 것이다. 다만 이 평가가 GPT-4o를 기준으로 하고 있다는 점에 유의해야 한다.
웹 개발자인 사이먼 윌슨 씨는 Qwen2.5-Coder-32B-Instruct를 메모리 64GB의 M2 탑재 맥북 프로에서 실제로 실행한 결과 Qwen2.5-Coder-32B-Instruct 크기가 충분히 작아 자신의 맥북 프로에서 다른 애플리케이션을 종료하지 않고도 모델을 실행할 수 있었고 속도와 결과 품질 모두 최고 수준 모델과 비교해도 손색이 없다고 느꼈다고 보고했다. 관련 내용은 이곳에서 확인할 수 있다.




