구글이 오픈소스 대규모 언어 모델 젬마(Gemma)를 공개했다. 젬마는 멀티모달 AI인 제미나이(Gemini)보다 경량이며 상용 이용도 가능하다.
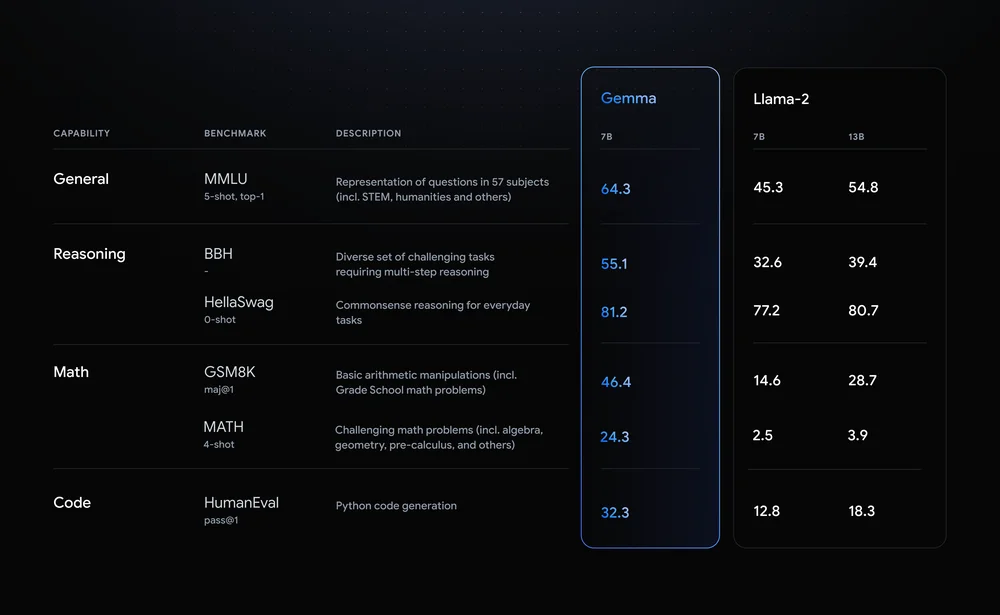
젬마에는 파라미터 수 20억인 젬마 2B와 파라미터 수 70억인 젬마 7B 2종류가 있다. 각각 사전 학습이 끝난 모델과 특정 태스크에 좁혀 조정한 인스트럭션 튜닝 완료 모델이 준비되어 있다. 또 젬마 이용 약관은 규모에 관계없이 모든 조직에 대해 상업적 이용과 배포를 허용한다.
젬마는 구글 클라우드 개발가 사용하는 여러 도구(Google Colab, Kaggle Notebook, JAX , PyTorch , Keras 3.0 , Hugging Face Transformers)를 지원하며 노트북과 워크스테이션 또는 구글 클라우드에서 실행할 수 있다.

구글은 또 엔비디아와 협력해 젬마를 구글 클라우드 TPU, 엔비디아 GPU에 최적화됐다고 밝히고 있다. 엔비디아에 따르면 엔비디아 지포스 RTX GPU로 동작 가능한 챗봇 AI인 챗위드RTX(Chat with RTX)로 선택할 수 있는 모델에 젬마가 추가될 예정이라고 한다.
또 젬마는 GKE(Google Kubernetes Engine)에 배포할 수 있으며 사전 구축된 기계학습 모델을 집약한 플랫폼(Vertex AI Model Garden)에도 추가됐다. 이를 통해 개발자는 자체 튜닝된 모델을 모든 규모 AI 애플리케이션을 강화할 수 있는 확장 가능한 엔드포인트로 쉽게 변환할 수 있다.
구글은 젬마와 동시에 책임적인 생성형 AI 툴킷도 출시했다. 책임 중시 설계, 견고하고 투명성 높은 평가, 책임 있는 개발 지원이라는 3가지 포인트로 이뤄진 책임적인 AI 개발을 호소하는 구글은 젬마는 AI 원칙을 최우선 젬마 사전 교육 모델을 안전하고 신뢰할 수 있도록 만드는 일환으로 자동화 기술을 사용해 학습 세트에서 특정 개인 정보와 기타 기밀 데이터를 제외했다고 밝혔다. 관련 내용은 이곳에서 확인할 수 있다.