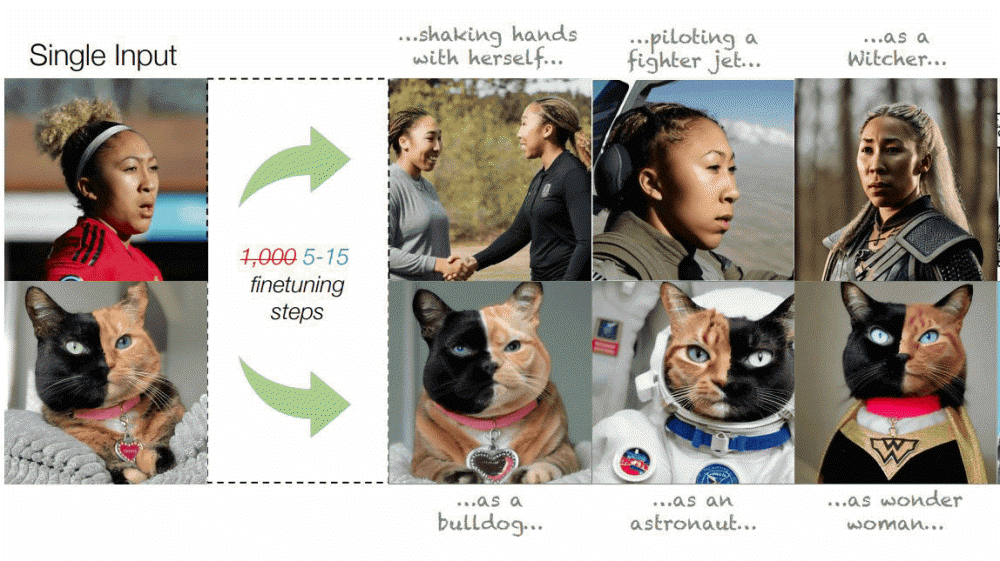
스테이블 디퓨전 등 이미지 생성 AI에 특정 이미지나 화풍을 특정 단어로 압축해 AI에 지시해 자신이 생성하고 싶은 이미지를 임의의 이미지와 닮은 최적화가 가능하다. 텔아비브대학 연구팀이 이미지 1장과 5∼15스텝 조정으로 이미지 최적화를 실현하는 방법을 발표했다.
스테이블 디퓨전으로 이미지 최적화를 가능하게 하는 기술 중 하나는 텍추얼 인버전(Textual Inversion)이다. 텍추얼 인버전은 임베딩(Embeddings)이라고도 불리는 기술로 스테이블 디퓨전 모델 데이터와는 별도로 이미지로부터 학습한 데이터를 준비하는 것만으로 특정 이미지와 유사한 이미지를 생성할 수 있게 한다. 텍추얼 인버전은 키워드 벡터화에 있어 가중치를 갱신할 뿐이어서 학습에 필요한 메모리가 비교적 적게 끝난다는 게 장점이다.
또 구글 이미지 생성 AI인 이메진(Imagen)용으로 개발된 이미지 최적화 기술이 드림 부스(Dream Booth)다. 텍추얼 인버전과 달리 드림 부스는 모델 자체에 추가 학습을 수행해 매개변수를 업데이트한다. 드림 부스는 스테이블 디퓨전에도 적용할 수 있는 방법이 개발됐다.

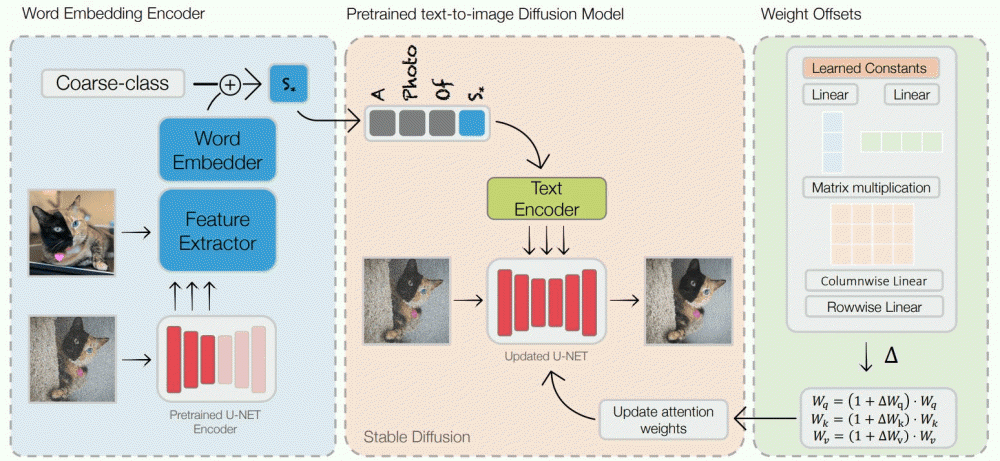
하지만 연구팀은 기존 이미지 최적화 접근법은 긴 학습 시간이나 높은 스토리지 요건 등이 문제라며 이런 문제를 해결하기 위한 인코더 기반 도메인 튜닝 접근법을 제안한다. 스테이블 디퓨전은 텍스터 인코더에 의해 입력된 텍스트를 768차원 토큰 임베디드 벡터로 출력하고 U-NET 인코더에 의해 해당 토큰 임베딩 벡터를 잠재 공간 내에서 노이즈 이미지 정보로 변환하고 디코더에 의해 해당 노이즈 이미지 정보를 픽셀 이미지에 출력하는 것으로 이미지를 생성한다.
이 접근법은 입력된 이미지 1장과 해당 이미지를 나타내는 단어 조합을 텍스터 인코더에 추가하고 또 U-NET 인코더를 갱신해 벡터 가중치를 바꾸는 2단계로 이뤄져 있다. 이 접근은 인물 얼글 외에서도 기능하는 것 외에 이미지 터치를 그대로 피사체를 바꾸도록 지시하거나 반대로 피사체를 그대로 화풍을 바꾸는 것도 가능하다고 한다. 다만 이 인코더 기반 접근은 VRAM 필요 용량이 대폭 증가한다. 또 텍스트 인코더와 U-NET 인코더를 동시에 튜닝해야 해서 많은 메모리가 필요하다. 아직 이 접근법을 수행하기 위한 코드를 공개하고 있지 않지만 조만간 깃허브에 공개할 예정이라고 한다. 관련 내용은 이곳에서 확인할 수 있다.