AI 훈련을 위해선 고품질 학습 데이터가 필수지만 이런 데이터가 급격히 고갈되고 있는 게 문제가 되고 있다. 엔비디아는 6월 14일 대규모 언어모델(LLM) 훈련에 사용할 합성 데이터 생성을 목적으로 개발됐으며 상용 애플리케이션에서도 사용 가능한 오픈소스 AI 모델 네모트론-4 340B(Nemotron-4 340B)를 발표했다.
네모트론-4 340B는 합성데이터 생성 파이프라인으로 사용할 수 있는 베이스(Base) 모델, 인스트럭트(Instruct) 모델, 리워드(Reward) 모델 등 3가지로 이뤄져 있으며 오픈소스 학습 프레임워크인 엔비디아 네모(nVIDIA NeMo)에서 작동하도록 최적화되어 있고 고속 추론용 엔비디아 TensorRT-LLM 라이브러리에서 사용할 수 있다. 또 네모트론-4 340B는 오픈 모델이면서도 토큰 9조 개와 컨텍스트 윈도 4,000개를 자랑하며 50개 이상 자연어와 40개 이상 프로그래밍 언어를 지원해 성능 면에서 메타 LlaMA3-70B와 앤트로픽 클로드(Claude) 3 소넷(Sonnet)을 능가하고 GPT-4에 필적할 것이라고 평가되고 있다.

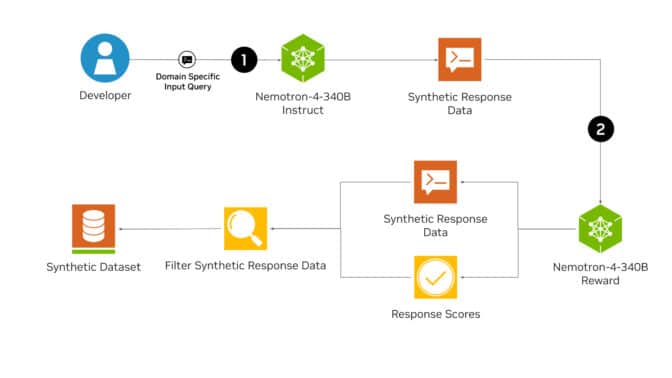
네모트론-4 340B를 사용한 합성데이터 생성 파이프라인을 보면 먼저 네모트론-4 340B 인스트럭트 모델이 다양하고 실전적인 합성데이터를 생성한다. 이를 평가 모델인 네모트론-4 340B 리워드가 유용성, 정확성, 일관성, 복잡성, 중복성 등 5가지 속성으로 평가하고 반복적인 개선과 정확성 검증을 수행한다. 네모트론-4 340B 리워드는 보상 모델 순위에서 1위를 차지했다.
네모트론-4 340B는 이미 허깅페이스에 공개되어 있으며 엔비디아 공식 사이트(ai.nvidia.com)에서도 곧 접근할 수 있을 것이라고 한다. 네모트론-4 340B를 써본 사용자 피드백은 압도적으로 호평이었고 그 중에서도 고성능과 방대한 전문 지식을 칭찬하는 목소리가 많았다.
보도에선 엔비디아는 네모트론-4 340B 출시로 LLM 훈련용 합성데이터 생성 분야에 혁신을 가져와 AI 혁신 선도자 입지를 다시 한번 견고히 했다고 평가하기도 했다. 관련 내용은 이곳에서 확인할 수 있다.