

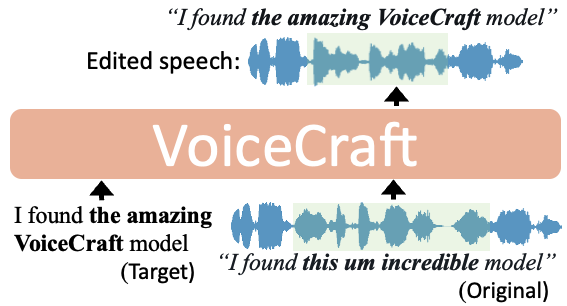
미국 텍사스 대학 오스틴 캠퍼스 연구팀이 학습 데이터 없이도 작동하는 제로샷 음성 편집‧음성 합성 기능을 가진 AI인 보이스크래프트(VoiceCraft)를 발표했다.
보이스크래프트는 텍스트와 이미지의 멀티모달 모델에서 아이디어를 얻어 제로샷 그러니까 모델이 학습 과정에서 배우지 않은 작업을 수행하는 방식으로 텍스트에서 음성 출력(Text-to-Speech), 음성 합성, 음성 편집이 가능한 신경 코덱 언어 모델(Neural Codec Language Models)이다.
보이스크래프트는 자연스럽게 음성을 편집할 수 있다. 보이스크래프트는 깃허브와 허깅페이스에서 공개되어 직접 사용해볼 수 있다. 관련 내용은 이곳에서 확인할 수 있다.




