
GPT-1은 1억 1,700만 개 파라미터를 갖는 언어 모델로 GPT-2에선 15억, GPT-3에선 1,750억으로 파라미터 수가 증가하면서 언어 모델 성능이 높아지고 있다. 하지만 매개변수 수가 증가하면서 학습에 필요한 데이터 수와 학습 중 사용되는 메모리량도 증가해 학습 비용이 크게 증가한다. 이런 가운데 메모리 소비량을 격감시키면서 적은 데이터로 학습할 수 있는 방법인 QLoRA가 등장했다.
LLMs 모델을 만들 때에는 먼저 대량 텍스트 데이터를 이용해 모델에 문자 취급 방법을 학습시킨다. 이렇게 만들어진 모델이 사전 학습된 모델이라고 불리는 모델로 대표적인 예로는 LLaMa나 RedPajama-INCITE가 있다. 이후 Q&A 등 고품질 데이터를 이용해 목적에 맞는 출력을 얻을 수 있도록 추가로 파인튜닝이라는 학습을 실시하는 흐름이 보통이다. 파인 튜닝만으로도 상당히 인간다운 대답을 할 수 있게 되지만 더 성능을 높이기 위해 인간으로부터의 평가를 모델에 피드백하는 인간 피드백에 의한 RLHF를 실시하는 경우도 있다.

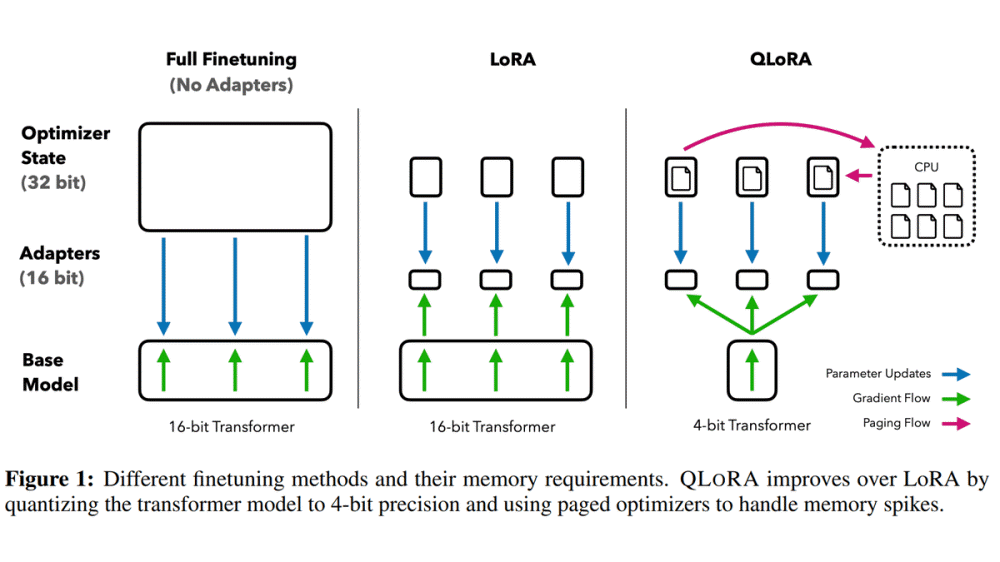
모델 파라미터 수는 첫 사전 학습을 실시하는 단계에서 정해져 버리기 때문에 파인튜닝 등 후 단계에선 바꿀 수 없다. 일반 기업에선 사전 학습할 때 필요한 엄청난 연산 비용을 지불할 수 없으므로 게시된 사전 학습 모델 중에서 매개변수 수를 선택한다. 보통 파라미터 수가 많을수록 성능이 높아지지만 동시에 파인 튜닝 비용이 점점 높아져 가는 문제가 발생했다.
파인 튜닝을 할 때에는 모델 전체를 메모리에 배치할 필요가 있는 건 물론 학습 대상 파라미터마다 조정을 위한 계산 결과를 메모리에 보존할 필요가 있어 모든 파라미터를 조정 대상으로 하는 기존 미세 조정은 원래 모델보다 몇 배 크기 메모리가 필요하다. 예를 들면 650억 파라미터 모델이라면 파라미터 1개당 16비트로 양자화하면 모델을 메모리 로딩하는 것만으로 650억×16비트 130GB분 메모리를 소비해 버리는 데 학습 방법 650GB 정도 계산 결과를 저장할 필요가 있어 파인 튜닝을 하기 위해선 합계로 780GB 분량 GPU 메모리가 필요했다.
이런 메모리 소비 문제를 해결하기 위해 고안된 게 LoRA라는 파인 튜닝 수법이다. LoRA는 원래 모델 파라미터 행렬을 낮은 순위로 근사한 새로운 행렬을 학습 대상으로 해 학습에 필요한 메모리 소비를 줄인다.
행렬을 저랭크 근사해 거대한 행렬을 비교적 작은 행렬 2개로 분해 가능하다. 만일 원래 모델 파라미터 행렬 크기가 [d]×[d]이었을 경우 저랭크 근사한 행렬은 랭크수를 [r]로서 [d]×[r]과 [r]×[d]라는 2개 행렬이 된다. 이렇게 하면 학습 대상 파라미터 수를 d의 제곱개에서 2×d×r개까지 줄일 수 있다. LoRA 논문에선 GPT-3 파인 튜닝으로 학습 대상 파마미터 수를 1만분의 1로 하고 메모리 소비량을 3분의 1로 했다고 말하고 있다.
LoRA는 적은 계산 자원으로 효율적으로 학습할 수 있기 때문에 개인 사용자 개발 의욕이 높은 이미지 생성 분야에서 이용이 진행되고 있었다. 예를 들어 스테이블 디퓨전에선 특정 도안이나 캐릭터, 배경 등을 LoRA로 학습시켜 이 학습 내용에 따른 이미지를 생성할 수 있다.
또 언어 모델 개발에 있어서도 계산 자원으로 우위에 서있는 구글 내부에선 LoRA를 경계하는 목소리가 나오는 것도 밝혀지고 있다. 이번 논문에선 이 LoRA를 기반으로 추가로 3가지 기술을 이용해 650억 파라미터 모델을 40GB 메모리만 탑재한 GPU로 학습 가능하게 한 데다 24시간 학습으로 챗GPT 99.3%에 필적하는 성능을 이끌어내는데 성공했다.
3가지 기술은 첫째 NF4에서의 양자화. 보통 언어 모델 양자화는 16비트로 이뤄지고 파마티러 1개당 16비트분 정보가 포함되어 있지만 QLoRA에선 대신에 4비트로 양자화를 실시하고 있다는 것. 정보량이 저하되는 분정도 떨어지지만 보통 사전 학습 끝난 모델 파라미터는 평균이 0의 정규 분포가 되기 때문에 정규 분포 기반으로 양자화를 실시하는 NF(NormalFloat) 형식으로 하는 것으로 정밀도 저하를 억제하고 있다.
둘째는 2중량자화. 양자화시에 사용하는 정수에 대해서도 양자화를 실시해 1파라미터당 0.5비트 필요했던 메모리 소비량을 0.127비트로 저하시켰다고 한다. 셋째는 페이지 최적화. GPU 메모리가 상한에 도달했을 때 일반 메모리에 데이터를 퇴피시켜 계산에 필요한 메모리를 확보하는 수법을 이용하는 것으로 파라미터를 갱신하는 피크시 GPU 메모리 사용량을 억제할 수 있었다고 한다.
Guanaco 33B를 QLoRA로 학습한 모델은 허깅페이스에서 시험할 수 있게 됐다. 영어로만 답할 수 있다. QLoRA 논문에서 사용된 코드는 깃허브에서 호스팅된다. 관련 내용은 이곳에서 확인할 수 있다.



