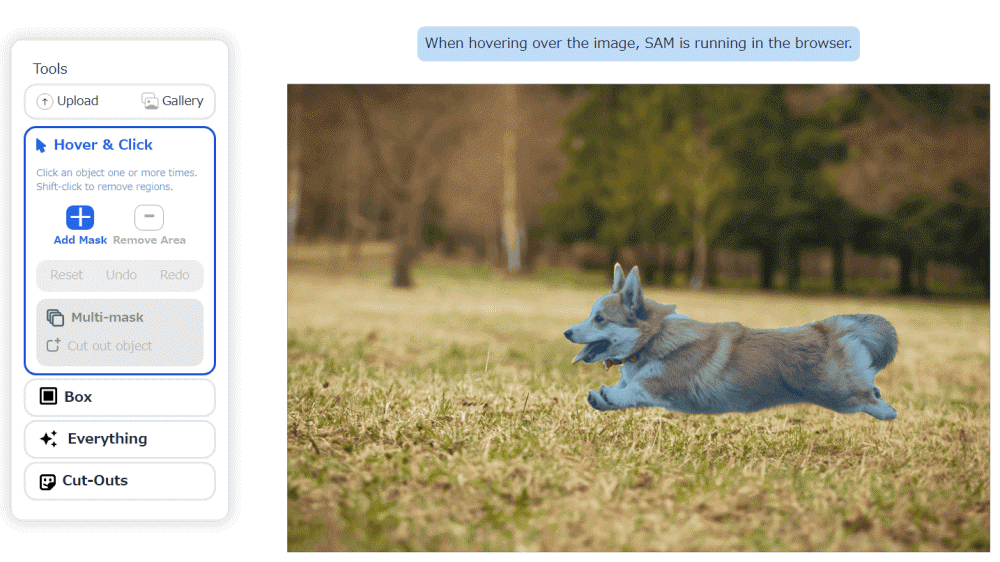
메타가 이미지나 동영상에 찍혀 있는 개별 객체를 학습하지 않은 것까지 식별할 수 있는 AI 모델인 SAM(Segment Anything Model)을 발표했다.
이미지와 동영상을 분할해 세그먼트별로 판별하는 이미지 세그멘테이션은 이미지 해석이나 처리를 용이하게 하기 위해 메타는 이미지 세그멘테이션이 웹페이지 콘텐츠 이해나 증강현실 앱, 이미지 편집에 도움이 된다고 보고 있다. 또 영상에 비친 동물이나 물체 위치를 자동 특정해 과학 연구에도 응용할 수 있다고 한다.
SAM은 이미지 세그멘테이션 모델로 이뤄져 있으며 텍스트 프롬프트나 사용자 클릭에 반응해 이미지 내 특정 객체를 분리할 수 있다. 이미지 세그멘테이션 기술 자체는 새로운 게 아니지만 학습 데이터세트에 존재하지 않는 객체도 식별 가능하다는 게 SAM의 특징이다.
메타에 따르면 보통 정밀도가 높은 이미지 세그멘테이션 모델을 만들려면 AI 학습 인프라와 신중하게 주석 첨부한 대량 데이터를 이용할 기준 전문가에 의한 고도의 전문 작업이 필요하지만 SAM은 이런 전문 교육과 전문 지식 필요성을 줄여 이미지 세그멘테이션 민주화를 실현, 컴퓨터비전 연구가 더 촉진될 것으로 기대하고 있다.
SAM 학습에 사용되는 SA-1B 데이터세트는 대형 사진 기업으로부터 라이선스를 받아 메타 데이터엔진에서 수집한 11억 개 고픔질 세그멘테이션 마스크로 이뤄져 있으며 아파치 2.0 오픈 라이선스 하에서 연구 목적 이용이 가능하다. 또 SAM 가중치 데이터를 뺀 소스 코드는 깃허브에 공개되어 있다. 관련 내용은 이곳에서 확인할 수 있다.