



정확한 문장을 생성하는 AI인 GPT-3과 문장에서 이미지를 생성하는 AI인 달리(DALL·E) 등을 개발하는 비영리단체인 오픈에이아이(OpenAI)가 새롭게 개발한 영상 인식 AI인 클립(CLIP)을 설명하고 있다.
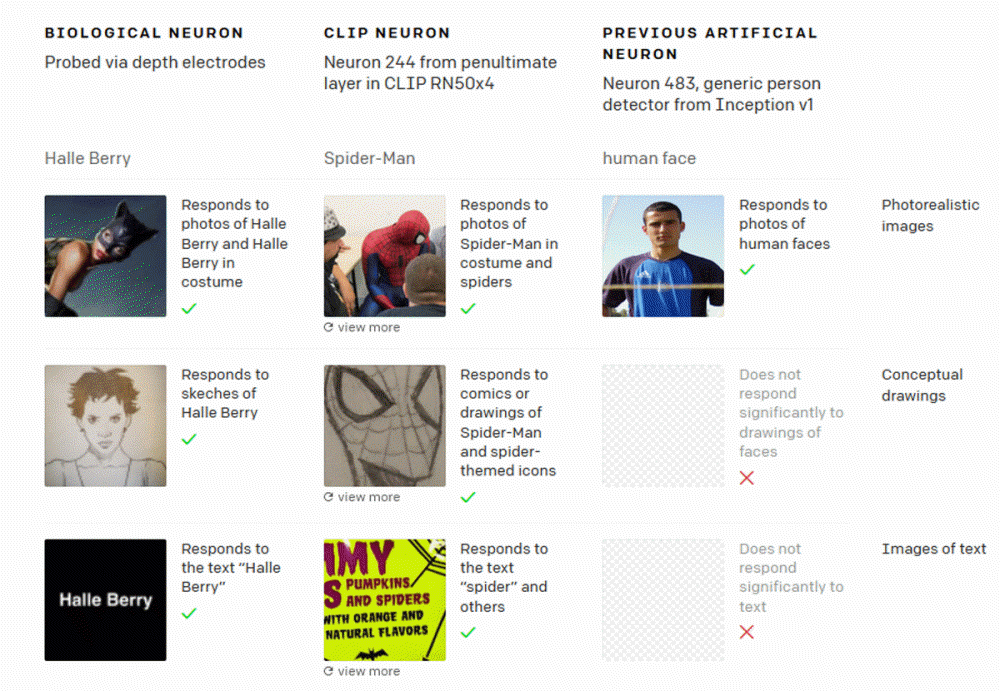
인간에게는 여배우 할리베리(Halle Berry) 사진이나 일러스트를 봐도 할리베리라는 텍스트라도 반응하는 뉴런처럼 여러 종류 정보에 균일하게 반응하는 뉴런이 존재하는 것으로 알려져 있다. 오픈에이아이에 따르면 클립은 인간처럼 다양한 형태 정보를 동일하게 처리할 수 있다.
인간 얼굴을 인간 얼굴로 인식하는 기존 이미지 인식 모델은 인간 얼굴 일러스트와 텍스트에서 인간 얼굴이라고 적힌 글에는 반응하지 않는다. 하지만 클립은 스파이더맨 코스프레 사진과 일러스트, 스파이더라는 문자열을 동일하게 처리할 수 있다.
또 클립은 다른 이미지 특징을 곱해 이미지를 인식한다. 예를 들어 저금통을 인식할 때 클립은 경제와 인형, 장난감 등 다른 요소를 곱하는 것으로 인식하고 있다. 또 클립은 요소 뺄셈도 실시하고 있다. 예를 들어 놀란다는 표정은 축복이나 포옹, 쇼크, 미소라는 표정과 함께 인식되어 있지만 친밀감이라는 표정은 부드러운 미소라는 표정 조합에서 질병 요소를 곁들여 인식하고 있다.
오픈에이아이는 클립의 약점도 설명하고 있다. 예를 들어 스탠더드 푸들 이미지는 그대로 스탠더드 푸들로 정확하게 인식할 수 있지만 이미지에 $ 표시를 여러 개 놔두면 저금통으로 인식해버린다. 또 아이패드라고 쓴 종이를 붙여 넣은 사과를 아이패드로 인식해버리는 경우도 있는 등 클립이 필기 인식이 뛰어난 게 화근이 되기도 한다. 오픈에이아이는 클립 분석에 이용한 도구를 공개하고 앞으로도 클립 관련 연구를 진행하면서 문제 해결에 나설 예정이다. 관련 내용은 이곳에서 확인할 수 있다.




