

최근 인공지능이 차별과 편견을 실시할 가능성이 위험시되면서 인공지능 알고리즘을 이용한 이미지 생성이 차별을 하고 있다는 페이스북 인공지능 분야 수석 연구원이 비난을 받아 트위터 계정을 중단하는 사태가 발생하기도 했다. 신경망을 훈련시키는 과정에서 데이트세트를 이용하지만 이 데이터세트가 차별의 원인이 되고 있다는 것으로 10년 이상 쓰여온 대규모 데이터세트를 연구자가 스스로 삭제했다.
기계학습에 의해 훈련된 AI는 훈련 과정에서 인간에 의해 만들어진 데이터세트를 읽는다. AI 자체가 차별과 편견을 스스로 생성하지는 않지만 데이터세트를 바탕으로 학습을 실시하는 구조여서 AI는 데이터세트에 포함된 차별과 편견을 그대로 이어받게 되는 것이다.
예를 들어 기계학습에 의해 훈련된 AI는 꽃과 음악 등을 재미와 연관하고 벌레와 무기라는 단어를 재미와 연결하지 않는 경향이 있다. 마찬가지로 여성이라는 말을 예술성과 연관시키는 반면 수학과의 연관은 어려운 경향이 있다. 이런 문제는 이전부터 지적되어 왔으며 인간 차별을 반영하지 않는 데이터세트 만들기가 중요시되고 있다.
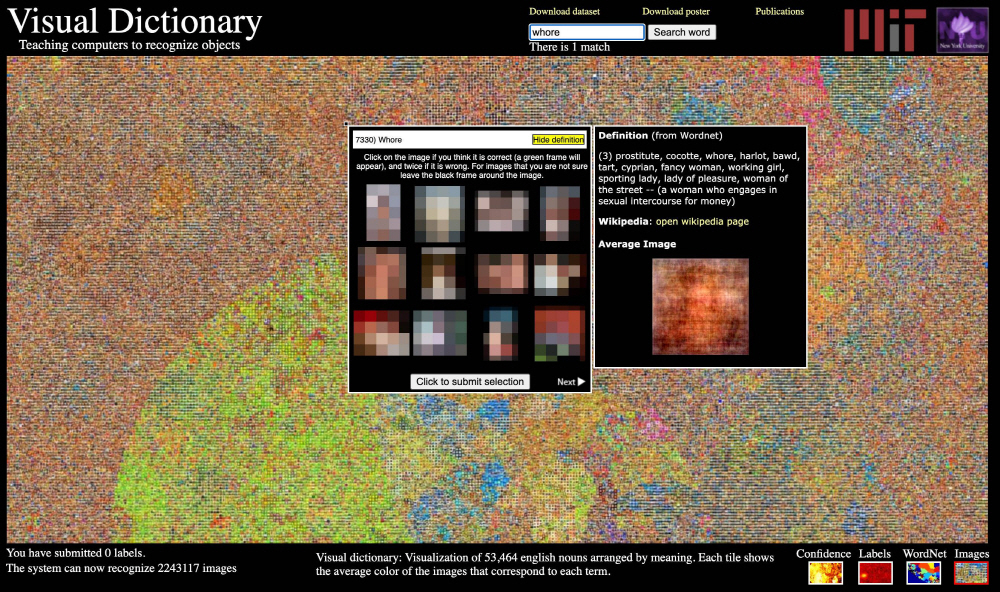
MIT는 지난 2008년 800억 장에 이르는 사진을 이용한 타이니 이미지(Tiny Images)라는 이미지 라이브러리를 만들었다. 이 이미지 라이브러리는 사진과 피사체 이름 라벨을 연결하고 컴퓨터 훈련에 쓰인다. 하지만 차세대 인증 서비스를 개발하는 유니파이아이디(UnifyID) 수석 과학자인 비나이 프라부(Vinay Prabhu), 유니버시티칼리지더블린 박사 과정 학생인 아베바 벌하니(Abeba Birhane)는 타이니 이미지에 대해 조사한 결과 이미지 수천 장이 아시아계와 흑인 차별 용어로 분류되어 있으며 여성을 설명하는데 잘못된 라벨도 사용한 것으로 판명됐다.
데이터세트에는 흑인 차별 용어로 분류된 원숭이 사진 혹은 매춘부라는 라벨을 붙인 수영복 차림 여성 사진, 음담패설로 분류한 해부학적 부위 등이 포함되어 있다. 이런 연관이 작성되면서 타이니 이미지를 이용해 훈련을 신경망에 의존하는 앱이나 웹사이트, 제품이 사진과 영상을 분석할 때 이 용어를 사용할 가능성이 지적되는 것이다.
이 문제에 대해 6월 29일(현지시간) MIT는 타이니 이미지를 온라인에서 완전 삭제했다. MIT 측에 따르면 타이니 이미지 데이터세트에 부적절한 용어가 포함된 데이터세트가 영어 개념 사전(WordNet)에 의해 자동으로 만들어진 데이터 수집에 의존하기 때문이라고 한다. 데이터세트는 상당히 크고 이미지는 32×32픽셀로 작기 때문에 수동 필터링이 어렵기 때문에 연구자가 수정을 추가하는 게 아니라 데이터세트 자체를 인터넷에서 삭제하는 결정을 내렸다고 한다.
한편 IBM은 지난 6월 기술이 차별과 불평등을 조장하는 걸 우려한다는 이유로 얼굴인식 시장에서 철수한다고 발표했다. 얼굴인식 소프트웨어는 수많은 국가에서 범죄 수사에 이용되고 있지만 이 역시 데이터세트 문제가 있어 흑인 인증 정밀도가 낮아 오인 체포 원인이 될 수 잇다는 문제가 지적된다. 관련 내용은 이곳에서 확인할 수 있다.