


음성 인식 알고리즘은 스마트 스피커나 스마트폰 등 다양한 디방이스와 애플리케이션에 챙용되면서 이제 일상 일부가 됐다. 하지만 애플과 아마존, 구글, IBM, 마이크로소프트 등이 선보인 음성 인식 알고리즘을 사용한 실험에서 음성 인식 알고리즘이 백인 목소리에 비해 흑인 못소리를 잘 인식할 수 없는 문제가 있다는 발견했다고 한다.
음성 인식 알고리즘은 스마트 도우미 조작이나 음성 입력, 문자 서비스 등 다양한 앱에 쓰인다. 음성 인식 시스템은 기계학습 알고리즘을 이용하며 개발자가 준비한 음성 데이터와 텍스터 데이터에 기계학습 알고리즘을 훈련시킨다.
스탠포드대학 연구팀은 이런 음성 인식 알고리즘 정확도를 조사하기 위해 애플과 아마존, 구글, IBM, 마이크로소프트의 음성 인식 알고리즘에 대해 당양한 사람이 말한 음성을 문자로 변환시키는 실험을 진행했다. 실험에 이용한 음성은 19.8시간 분량이며 백인 42명과 흑인 73명이 말한 음성 2,141개로 이뤄져 있다. 또 화자 중 44%는 남성이며 평균 연령은 45세였다.
실험 결과 각사 음성 인식 알고리즘은 평균 백인이 말한 단어 중 19%를 오인했지만 흑인이 말한 단어 오인 비율은 35%에 달했다. 또 오류 비율은 흑인 남성 전체 중 41%, 흑인 여성 오류 비율은 30%였다.

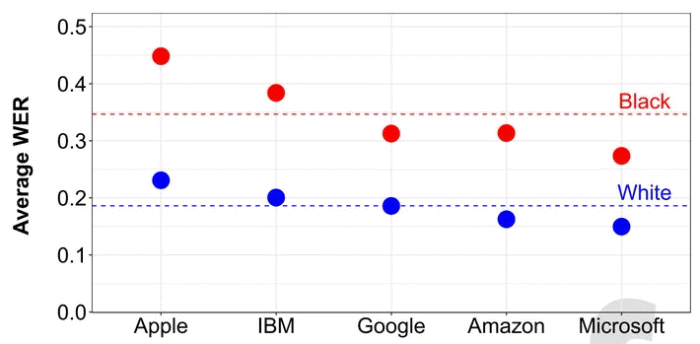
어떤 음성 인식 알고리즘에서도 흑인 쪽 오류 비율이 백인 쪽을 상회한다. 애플 음성인식 알고리즘의 경우 가장 오류 비율이 높아 흑인 오류율은 45%, 백인은 23%를 나타냈다. 가장 성적이 좋은 마이크로소프트 쪽도 흑인 오류율은 27%, 백인은 15%를 나타냈다.
연구팀은 이 결과는 특정 기업에 국한된 게 아니며 5곳 모두 유사한 패턴을 보였다고 밝혔다. 과거에도 알고리즘과 소프트웨어가 인종 편견이 있다는 케이스가 보고된 바 있다. 구글 포토가 흑인을 고릴라로 인식하고 태그를 달아버린 사례나 인종 관련 데이터가 존재하지 않는 의료 시스템에서 흑인이 불평등하게 평가되는 사례도 있었다.
이런 문제는 기계학습 알고리즘을 훈련시키기 위한 데이터세트에 존재하는 편향이 원인일 가능성이 높다. 훈련에 이용한 데이터 자체가 백인 화자 음성을 풍부하게 포함하고 있으며 흑인 화자 음성을 별로 포함하지 않으면 음성 인식 알고리즘은 흑인 화자 억양이나 말투를 잘 학습할 수 없고 오류 비율이 높아진다. 연구팀은 개발자가 음성 인식 알고리즘을 훈련시키는데 더 다양한 데이터를 이용할 필요가 있다는 걸 보여준다고 지적한다.
이 결과에 대해 구글 측은 공평성이 구글 AI의 기본 원칙 중 하나이며 몇 년간 음성 인식 알고리즘 정확도 향상에 노력을 기울이고 있다면서 앞으로도 계속할 것이라고 밝혔다. IBM 측은 자연어와 음성 처리 기능 개발과 개선, 발전을 계속하고 IBM 왓슨을 통해 사용자 기능 수준을 향상시키도록 노력하겠다고 말했다. 아마존은 음성 인식 알고리즘을 지속적으로 개선하고 있는지에 대한 설명을 웹페이지에 제공 중이다. 관련 내용은 이곳에서 확인할 수 있다.